

HTA 101: V. ECONOMIC ANALYSIS METHODS
- A. Main Types of Economic Analysis in HTA
- B. Key Attributes of Cost Analysis
- C. Cost-Effectiveness Plane
- D. Cost-Utility Analysis Using Cost per QALY
- E. Role of Budget Impact Analysis
- F. Collecting Cost Data in Clinical Studies
- References for Chapter V
Studies of costs and related economic implications comprise a major group of methods used in HTA. These studies can involve attributes of either or both of primary data collection and integrative methods. That is, cost data can be collected, for example, as part of RCTs and other clinical studies as well as administrative (“claims”) databases used in health care payment. Cost data from one or more such sources often are combined with data from primary clinical studies, epidemiological studies, and other sources to conduct cost-effectiveness analyses and other analyses that involve weighing health and economic impacts of health technology.
Interest in cost analyses has accompanied concerns about rising health care costs, pressures on health care policymakers to allocate resources, and the need for health product makers and other technology advocates to demonstrate the economic benefits of their technologies. This interest is reflected in a great increase in the number of reports of cost analyses in the literature and further refinement of these methods.
A. Main Types of Economic Analysis in HTA
There is a variety of approaches to economic analysis, the suitability of any of which depends on the purpose of an assessment and the availability of data and other resources. It is rarely possible or necessary to identify and quantify all costs and all outcomes (or outputs or benefits), and the units used to quantify these may differ.
Main types of economic analysis used in HTA include the following.
- Cost-of-illness analysis: a determination of the economic impact of an illness or condition (typically on a given population, region, or country) e.g., of smoking, arthritis, or diabetes, including associated treatment costs
- Cost-minimization analysis: a determination of the least costly among alternative interventions that are assumed to produce equivalent outcomes
- Cost-effectiveness analysis (CEA): a comparison of costs in monetary
units with outcomes in quantitative non-monetary units, e.g., reduced mortality
or morbidity
- Cost-utility analysis (CUA): a form of cost-effectiveness analysis that compares costs in monetary units with outcomes in terms of their utility, usually to the patient, measured, e.g., in QALYs
- Cost-consequence analysis: a form of cost-effectiveness analysis that presents costs and outcomes in discrete categories, without aggregating or weighting them
- Cost-benefit analysis (CBA): compares costs and benefits, both of which are quantified in common monetary units.
- Budget-impact analysis (BIA): determines the impact of implementing or adopting a particular technology or technology-related policy on a designated budget, e.g., of a drug formulary or health plan.
The differences in valuation of costs and outcomes among these alternative are shown in Box V-1.
Box V-1. Types of Economic Analysis Used in HTA
| Analysis Type | Valuation of costs1 | Valuation of outcomes | |
|---|---|---|---|
| Cost of Illness | $ | vs. | None |
| Cost Minimization | $ | vs. | Assume same |
| Cost Effectiveness | $ | ÷ | Natural units |
|
$ | vs. | Natural units |
|
$ | ÷ | Utiles (e.g., QALYs) |
| Cost Benefit | $ | ÷ or2 - | $ |
| Budget Impact | $ | vs. | None3 or maximize various4 |
1Any currency
2Cost-benefit ratio (¸) or net of costs and benefits (-)
3That is, determine impact of an intervention/program on a designated
non-fixed budget
4That is, maximize some outcome within a designated fixed (“capped”)
budget"
Cost-minimization analysis, CEA and CUA necessarily involve comparisons of alternative interventions. A technology cannot be simply cost effective on its own, though it may be cost effective compared to something else.
Because it measures costs and outcomes in monetary (not disease-specific) terms, CBA enables comparison of disparate technologies, e.g., coronary artery bypass graft surgery and screening for breast cancer. A drawback of CBA is the difficulty of assigning monetary values to all pertinent outcomes, including changes in the length or quality of life. CEA avoids this limitation by using more direct or natural units of outcomes such as lives saved or strokes averted. As such, CEA can only compare technologies whose outcomes are measured in the same units. In CUA, estimates of utility are assigned to health outcomes, enabling comparisons of disparate technologies.
Two basic approaches for CBA are the ratio approach and the net benefit approach. The ratio approach indicates the amount of benefits (or outcomes) that can be realized per unit expenditure on a technology vs. a comparator. In the ratio approach, a technology is cost beneficial vs. a comparator if the ratio of the change in costs to the change in benefits is less than one. The net benefits approach indicates the absolute amount of money saved or lost due to a use of a technology vs. a comparator. In the net benefits formulation, a technology is cost-beneficial vs. a comparator if the net change in benefits exceeds the net change in costs. The choice between a ratio approach and a net benefits approach for a CBA can affect findings. The approach selected may depend upon such factors as whether costs must be limited to a certain level, whether the intent is to maximize the absolute level of benefits, whether the intent is to minimize the cost/benefit ratio regardless of the absolute level of costs, etc. Indeed, under certain circumstances these two basic approaches can yield different preferences among alternative technologies. shows basic formulas for determining CEA, CUA, and CBA.
Box V-2. Basic Formulas for CEA, CUA, and CBA
A: Technology A
C: Technology C (a comparator)
Cost-Effectiveness Ratio:
$CostA -
$CostC
CB Ratio = ___________________
EffectA -EffectC
For example: “$45,000 per life-year saved” or “$10,000 per lung cancer case averted”
Cost-Utility Ratio:
$CostA -
$CostC
CU Ratio = ___________________
UtileA -
UtileC
Utiles, units of utility or preference, are often measured in QALYs. So, for example: “$150,000 per QALY gained” or “$12,000 per QALY gained”
Cost-Benefit, Ratio Approach:
$CostA -
$CostC
CB Ratio = ________________________
$BenefitA
- $BenefitC
For example: “Cost-benefit ratio of 1.2”
Cost-Benefit, Net Benefit Approach:
CB Net = ($CostA - $CostC)
– ($BenefitA - $BenefitC)
For example: “Net cost of $10,000”
B. Key Attributes of Cost Analyses
The approaches to accounting for costs and outcomes in cost analyses can vary in a number of important respects, such as choice of comparator, perspective of economic analysis, and time horizon of analysis. A basic “checklist” of these attributes is shown in Box V-3, and some are described briefly below. These attributes should be carefully considered by investigators who design and conduct cost analyses, assessors who review or appraise reports of these analyses, and policymakers who intend to make use of findings based on these analyses. Given the different ways in which costs and outcomes may be determined, all studies should make clear their methodology in these respects.
Box V-3. Attributes to Consider When Designing and Reviewing Cost Analyses
- Comparator
- Perspective
- Outcomes/endpoints selected
- Efficacy vs. effectiveness
- Data capture method
- Direct costs (health care and non-health care)
- Indirect costs (e.g., loss of productivity)
- Actual costs vs. charges/prices
- Marginal costs vs. average costs
- Time horizon of analysis
- Discounting
- Correction for inflation
- Modeling use
- Sensitivity analysis
- Reporting results
- Funding source
Comparato. Any cost analysis of one intervention versus another must be specific about the comparator. This may be standard of care (current best practice), minimum practice, or no intervention. Some analyses that declare the superiority of a new intervention may have used a comparator that is no longer in practice or is considered sub-standard care or that is not appropriate for the patient population of interest.
Perspective. The perspective of a cost analysis refers to the standpoint at which costs and outcomes are realized. For instance, the perspective may be that of society overall, a third-party payer, a physician, a hospital, or a patient. Clearly, costs and outcomes are not realized in the same way from each of these perspectives. Many analysts favor using the broad societal perspective that seeks to identify all costs and all outcomes accordingly. However, “society” as such may not be the decision maker, and what is cost effective from that perspective may not be what is cost effective from the standpoint of a ministry of health, insurance company, hospital manager, patient, or other decision maker. It is possible that this perspective may resemble that of a national or regional government, if indeed that government experiences (or is responsible for representing the perspectives of those that experience) all of the costs and outcomes that are included in a societal perspective.
Direct costs. Direct costs represent the value of all goods, services, and other resources consumed in providing health care or dealing with side effects or other current and future consequences of health care. Two types of direct costs are direct health care costs and direct non-health care costs.
Direct health care costs include costs of physician services, hospital services, drugs, etc. involved in delivery of health care. Direct non-health care costs are incurred in connection with health care, such as for care provided by family members and transportation to and from the site of care. In quantifying direct health care costs, many analyses use readily available hospital or physician charges (i.e., taken from price lists) rather than true costs, whose determination may require special analyses of resource consumption. Charges (as well as actual payments) tend to reflect provider cost-shifting and other factors that decrease the validity of using charges to represent the true costs of providing care.
Indirect costs. Analyses should account for indirect costs, sometimes known as “productivity losses.” These include the costs of lost work due to absenteeism or early retirement, impaired productivity at work (sometimes known as “presenteeism”), and lost or impaired leisure activity. Indirect costs also include the costs of premature mortality. Intangible costs of pain, suffering, and grief are real, yet very difficult to measure and are often omitted from cost analyses.
Time horizon. Interpretation of cost analyses must consider that the time horizon (or time-frame) of a study is likely to affect the findings regarding the relative magnitudes of costs and outcomes of a health care intervention. Costs and outcomes associated with a particular intervention usually do not accrue in steady streams over time. As suggested in Box V-4, where most of the health benefits resulting from investing in a health program are realized years after most of the spending, any determination of the cost effectiveness of a particular health program can vary widely depending on the time horizon (e.g., 5, 10, 15, or 20 years since inception of the program) of the analysis. The meaningful time horizons for assessing the cost effectiveness of, e.g., emergency appendectomies, cholesterol-lowering in high-risk adults, and smoking prevention in teenagers are likely to be quite different. For example, an analysis conducted for the Medicare program in the US to determine cost and time tradeoffs of hemodialysis and kidney transplantation showed that the annualized expenditure by the Medicare End-Stage Renal Disease Program for a dialysis patient was $32,000. Although patients with functioning transplanted kidneys required a first-year expenditure of $56,000, they cost Medicare only an average of $6,400 in succeeding years. On average, estimated cumulative dialysis and transplantation costs reached a break-even point in about three years, after which transplantation provided a net financial gain compared to dialysis, according to the analysis (Rettig 1991).
Box V-4. Time Horizon of Economic Analysis
Determination of cost effectiveness can depend on relative accruals of costs and health benefits at selected time horizon of analysis. Here, improvements in population health lag behind (are delayed relative to) costs. What is an appropriate time to conduct a cost-effectiveness analysis?
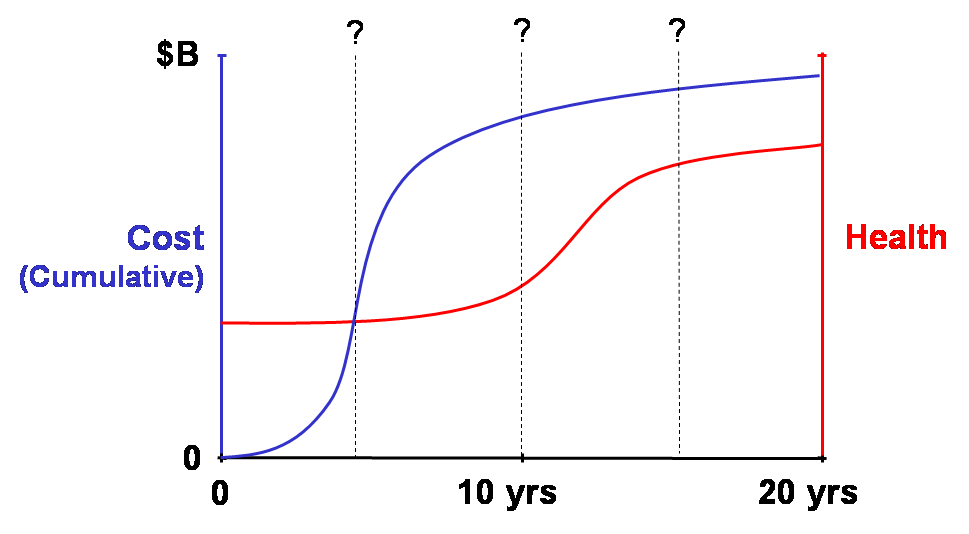
Time horizons should be long enough to capture streams of health and economic outcomes (including significant intended and unintended ones). These could encompass a disease episode, patient life, or even multiple generations of life (such as for interventions in women of child-bearing age or interventions that may cause heritable genetic changes). Quantitative modeling approaches may be needed to estimate costs and outcomes that are beyond those of available data. Of course, the higher the discount rate used in an analysis, the less important are future outcomes and costs.
Average costs vs. marginal costs. Assessments should make clear whether average costs or marginal costs are being used in the analysis. Whereas average cost analysis considers the total (or absolute) costs and outcomes of an intervention, marginal cost analysis considers how outcomes change with changes in costs (e.g., relative to the standard of care or another comparator), which may provide more information about how to use resources efficiently. Marginal cost analysis may reveal that, beyond a certain level of spending, the additional benefits are no longer worth the additional costs. For example, as shown in Box V-5, the average cost per desired outcome of a protocol of iterative screening tests may appear to be quite acceptable (e.g., $2,451 per case of colorectal cancer detected assuming a total of six tests per person), whereas marginal cost analysis demonstrates that the cost of adding the last test (i.e., the additional cost of the sixth test per person) to detect another case of cancer would be astronomical.
Discounting. Cost analyses should account for the effect of the passage of time on the value of costs and outcomes. Costs and outcomes that occur in the future usually have less present value than costs and outcomes realized today. Discounting reflects the time preference for benefits earlier rather than later; it also reflects the opportunity costs of capital, i.e., whatever returns on investment that could have been gained if resources had been invested elsewhere. Thus, costs and outcomes should be discounted relative to their present value (e.g., at a rate of 3% or 5% per year). Discounting allows comparisons involving costs and benefits that flow differently over time. It is less relevant for “pay-as-you-go” benefits, such as if all costs and benefits are realized together within the same year. It is more relevant in instances where these do not occur in parallel, such as when most costs are realized early and most benefits are realized in later years. Discount rates used in cost analyses are typically based on interest rates of government bonds or the market interest rates for the cost of capital whose maturity is about the same as the duration of the effective time horizon of the health care intervention being evaluated. Box V-6 shows the basic formula for calculating present values for a given discount rate, as well as how the present value of a cost or benefit that is discounted at selected rates changes over time.
Cost analyses should also correct for the effects of inflation (which is different from the time preference accounted for by discounting), such as when cost or cost-effectiveness for one year is compared to another year.
Sensitivity analysis. Any estimate of costs, outcomes, and other variables used in a cost analysis is subject to some uncertainty. Therefore, sensitivity analysis should be performed to determine if plausible variations in the estimates of certain variables thought to be subject to significant uncertainty affect the results of the cost analysis. A sensitivity analysis may reveal, for example, that including indirect costs, or assuming the use of generic as opposed to brand name drugs in a medical therapy, or using a plausible higher discount rate in an analysis changes the cost-effectiveness of one intervention compared to another.
Box V-5. Average Cost Analysis vs. Marginal Cost Analysis
The importance of determining marginal costs is apparent in this analysis of a proposed protocol of sequential stool guaiac testing for colon cancer. Here, average cost figures obscure a steep rise in marginal costs of testing because the high detection rate from the initial tests is averaged over subsequent tests that contribute little to the detection rate. This type of analysis helps to demonstrate how it is possible to spend steeply increasing health care resources for diminishing returns in health benefits.
Cancer screening and detection costs with sequential guaiac tests
| No. of tests | No. of cancers detected | Additional cancers detected | Total cost of diagnosis ($) | Additional cost of diagnosis ($) | Average cost per cancer detected ($) | Marginal cost per cancer detected ($) |
| 1 | 65.9469 | 65.9469 | 77,511 | 77,511 | 1,175 | 1,175 |
| 2 | 71.4424 | 5.4956 | 107,690 | 30,179 | 1,507 | 5,492 |
| 3 | 71.9004 | 0.4580 | 130,199 | 22,509 | 1,810 | 49,150 |
| 4 | 71.9385 | 0.0382 | 148,116 | 17,917 | 2,059 | 469,534 |
| 5 | 71.9417 | 0.0032 | 163,141 | 15,024 | 2,268 | 4,724,695 |
| 6 | 71.9420 | 0.0003 | 176,331 | 13,190 | 2,451 | 47,107,214 |
This analysis assumed that there were 72 true cancer cases per 10,000 population. The testing protocol provided six stool guaiac tests per person to detect colon cancer. If any one of the six tests was positive, a barium-enema test was performed, which was assumed to yield no false-positive and no false-negative results. Other assumptions: the true-positive cancer detection rate of any single guaiac test was 91.667%; the false-positive rate of any single guaiac test was 36.508%; the cost of the first stool guaiac test was $4 and each subsequent guaiac test was $1; the cost of a barium-enema was $100. The marginal cost per case detected depends on the population screened and the sensitivity of the test used.
From: N Engl J Med, Neuhauser D, Lewicki AM. What do we gain from the sixth stool guaiac? 293:226-8. Copyright © 1975 Massachusetts Medical Society. Reprinted with permission from Massachusetts Medical Society.
While cost analysis methods are generally becoming more harmonized, considerable variation in their use remains. Although some variation is unavoidable, some differences in economic perspective, accounting for direct and indirect costs, time horizon, discounting and other aspects are arbitrary, result from lack of expertise, and may reflect biases on the part of investigators or study sponsors (Elixhauser 1998; Hjelmgren 2001; Nixon 2000). Guidelines and related standards for conducting costs analyses in HTA have evolved, especially since the 1990s, helping to improve their quality, reporting, and interpretation of their findings (Byford 1998; Drummond 2005; Eccles 2001; Gold 1996; Husereau 2013; Mauskopf 2007; McGhan 2009; Weinstein 1977). Also, HTA agencies and collaborations are increasingly transparent about their methods involving economic analyses (IQWiG 2009; Wonderling 2011).
Box V-6. Discount Rate Calculation and Use in
Determining Present Value of Future Costs and Benefits
Discount rate calculation: compiling the discounted stream of costs (or benefits)
over time: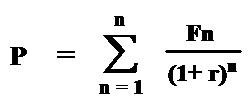
P = present value
F = future cost (or benefits) at
year n
r = annual discount rate
Present value (P) of future cost (F) occurring at year n at selected annual discount rate (r):
Discount Rate
| Year | 3% | 5% | 10% |
|---|---|---|---|
| 1 | 0.97 | 0.95 | 0.91 |
| 5 | 0.86 | 0.78 | 0.62 |
| 25 | 0.48 | 0.30 | 0.09 |
| 50 | 0.23 | 0.09 | 0.009 |
- For example, the present value of a cost
(or benefit) of $1,000 occurring:
- 1 year in the future, using 10% discount rate, is $910
- 5 years in the future, using 3% discount rate, is $860
- 50 years in the future, using 5% discount rate, is $90
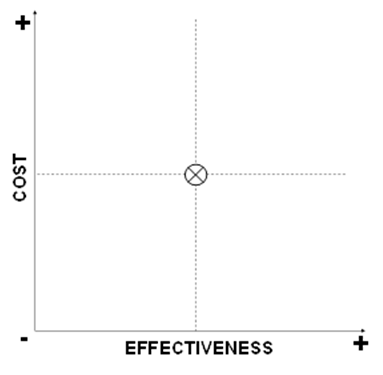
Cost-Effectiveness Plane
A basic approach to portraying a cost-effectiveness (or cost-utility) comparison of a new intervention to a standard of care is to consider the cost and effectiveness of the new intervention in four quadrants of a cost-effectiveness plane as shown in Box V-7. Starting with the upper graph, the level of costs and the level of effectiveness for the current standard of care are indicated by the “X” at the center. A new intervention may have higher or lower costs, and higher or lower effectiveness, such that its plot may fall into one of the four quadrants surrounding the costs and effectiveness of the standard of care. As shown in the middle graph, if the plot of the new intervention falls into either of two of the quadrants, i.e., where the new intervention has higher costs and lower effectiveness (indicating that it is “dominated” and should be rejected), or it has lower costs and higher effectiveness (indicating that it is “dominant” and should be adopted), then no further analysis may be required. If it is known that the plot of the new intervention falls into either of the other two quadrants, i.e., where the new intervention has higher costs and higher effectiveness, or it has lower costs and lower effectiveness, then further analysis weighing the marginal costs and effectiveness of the new intervention compared to the standard of care may be required.
Box V-7. Quadrants of Cost Effectiveness
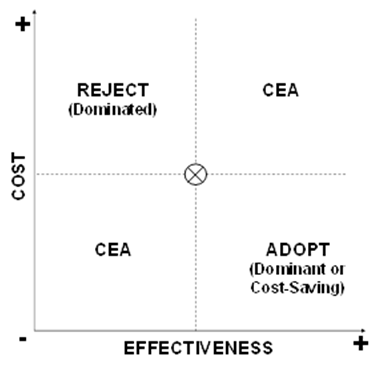

Within either of the two quadrants that entail weighing tradeoffs of costs and effectiveness, it may be apparent that the marginal tradeoff of costs and outcomes is so high or low as to suggest rejection or adoption. As shown in the lower graph of Box V-7, this arises when the new intervention yields only very low marginal gain in effectiveness at a very high marginal cost (Reject?), or yields very high marginal improvements in effectiveness at a very low marginal cost (Adopt?).
D. Cost-Utility Analysis Using Cost per QALY
As noted above, QALYs are often used in cost-utility analysis for the purposes of optimizing allocation of health care spending to maximize QALYs gained, and thereby maximize social welfare. Cost per QALY gained, i.e., the marginal (additional or incremental) cost required to gain 1.0 QALY by using a technology, is one means to quantify the value to society of using that technology instead of the alternative(s). Because the QALY incorporates length of life and quality of life but is not specific to any particular disease state or condition, it enables cost-utility comparisons across virtually the entire spectrum of health care interventions.
As shown in Box V-8, a cost per QALY analysis can account for large differences in technology costs, survival, and quality of life. Here, cost utilities are compared for three alternative therapies for a particular disease, end-stage heart disease.
An early, controversial example of using cost-utility analysis to assess the relative societal benefits of a diverse range of technologies is shown in Box V-9. In this type of list (sometimes known as a “league table”), allocating health care spending for the technologies higher on the list is more efficient (i.e., purchases the next QALY at lower cost and therefore enables maximizing the QALYs purchased) than allocating those resources to technologies further down the list. That is, the technologies on that list are arranged in order of greatest to least cost utility.
Box V-8. Cost-Utilities for Alternative Therapies for End-Stage Heart Disease
Outcomes and Costs by Therapy*
| Therapy | Life years gained (yr) | Mean utility | QALY gained (yr) | Aggregate cost ($) |
| A. Conventional medical treatment | 0.50 | 0.06 | 0.03 | 28,500 |
| B. Heart transplantation | 11.30 | 0.75 | 8.45 | 298,200 |
| C. Total artificial heart (TAH) | 4.42 | 0.65 | 2.88 | 327,600 |
*Costs and outcomes were discounted at 3% per year; 20-year horizon. Mean utilities derived using time-tradeoff method on scale for which 1.0 was well, 0.0 was death, and states worse than death were valued between 0.0 and -1.0.
Cost-Utility Ratios for Therapy Comparisons
| Comparison | Incremental QALY (yr) | Incremental Cost ($) | Marginal Cost per QALY ($/yr) |
|---|---|---|---|
| Heart transplantation vs. Conventional medical (B – A) | 8.42 | 269,700 | 32,031 |
| Total artificial heart vs. Conventional medical (C – A) | 2.85 | 299,100 | 104,947 |
| Total artificial heart vs. Heart transplantation (C – B) | -5.57 | 29,400 | Dominated |
This cost-utility comparison indicates that, for patients with end-stage heart disease, both heart transplantation and the total artificial heart yield more quality-adjusted life years at higher costs compared to conventional medical therapy. However, the cost-utility ratio of heart transplantation vs. conventional medical treatment is preferred to (i.e., lower than) the cost-utility ratio of total artificial heart vs. conventional medical therapy. Also, compared to heart transplantation, the total artificial heart costs more and results in fewer quality-adjusted life years, and therefore the total artificial heart is “dominated” by heart transplantation.
Adapted from estimates provided in: Hogness JR, Van Antwerp M. The Artificial Heart: Prototypes, Policies, and Patients. Washington, DC: National Academy Press; 1991.
Box V-9. Cost per QALY for Selected Health Care Technologies
| Health Care Technology | Cost per QALY (£ 1990) |
|---|---|
| Cholesterol testing and diet therapy (all 40-69 yrs) | 220 |
| Neurosurgery for head injury | 240 |
| General practitioner advice to stop smoking | 270 |
| Neurosurgery for subarachnoid hemorrhage | 490 |
| Antihypertensive therapy to prevent stroke (45-64 yrs) | 940 |
| Pacemaker implantation | 1,100 |
| Hip replacement | 1,180 |
| Valve replacement for aortic stenosis | 1,140 |
| Cholesterol testing and treatment | 1,480 |
| Coronary artery bypass graft surgery (left main disease, severe angina) | 2,090 |
| Kidney transplant | 4,710 |
| Breast cancer screening | 5,780 |
| Heart transplantation | 7,840 |
| Cholesterol testing and treatment (incremental) (all 25-39 yrs) | 14,150 |
| Home hemodialysis | 17,260 |
| Coronary artery bypass graft surgery (one-vessel disease, moderate angina) | 18,830 |
| Continuous ambulatory peritoneal dialysis | 19,870 |
| Hospital hemodialysis | 21,970 |
| Erythropoietin for dialysis anemia (with 10% reduction in mortality) | 54,380 |
| Neurosurgery for malignant intracranial tumors | 107,780 |
| Erythropoietin for dialysis anemia (with no increase in survival) | 126,290 |
This table ranks selected procedures for a variety of health problems according to their cost utility, (i.e., the amount of money that must be spent on each procedure to gain one more QALY). There were some methodological differences in determining costs and QALYs among the studies from which these results were derived. Nonetheless, giving considerable latitude to these figures, the range in the magnitude of investment required to yield the next QALY for these treatments is great. This type of "bucks for the bang" (here, British pounds for the QALY) analysis helps to illustrate implicit choices made in allocating scarce health care resources, and suggests how decision makers might move toward reallocating those resources if the allocation rule is intended to optimize societal gain in net health benefits (e.g., as measured using QALYs).
In some instances, the impact of a technology on survival may be sufficiently great as to diminish its relative impact on HRQL, such that there is little need to adjust survival for HRQL. In other instances, the impact of an intervention on HRQL is great, and adjusting survival for it to determine the QALYs gained will affect the relative cost-utility of alternative interventions (Chapman 2004; Greenberg 2011).
An example of a league table of costs per DALY gained for several interventions in low-to-middle-income countries is shown in Box V-10.
Box V-10. Cost per DALY Gained for Selected Interventions in
Low- and Middle-Income Countries
| Intervention | Cost per DALY1 (US$) |
|---|---|
| Basic childhood vaccines | 7 |
| Tuberculosis treatment2 | 102 |
| Improved emergency obstetric care3 | 127 |
| Polypill to prevent heart disease | 409 |
| Drug and psychosocial treatment of depression | 1,699 |
| Coronary artery bypass graft | 37,000 |
1Cost per DALY represents an average for low- and middle-income countries, except where noted.
2Directly observed treatment short course (DOTS) for epidemic infectious tuberculosis
3Refers to South Asia only; includes measures to address life-threatening complications
Source: Disease Control Priorities Project, Using Cost-Effectiveness Analysis for Setting Health Priorities. March 2008. Calculations based on Chapters 2, 16, 26, and 33 of: Jamison DT, Breman G, Measham AR, et al., eds., Disease Control Priorities in Developing Countries. 2nd ed. New York: Oxford University Press; 2006.
Certain methodological aspects and the proposed use of QALYs or similar units in setting health care priorities remain controversial (Arnesen 2000; Gerard 1993; Nord 1994; Ubel 2000). Research on public perceptions of the value of health care programs indicates that health gain is not necessarily the only determinant of value, and that an approach of maximizing QALYs (or other HALY or similar measure) per health expenditure to set priorities may be too restrictive, not reflecting public expectations regarding fairness or equity. For example, because people who are elderly or disabled may have a lower “ceiling” or potential for gain in QALYs (or other measure of HRQL) than other people would have for the same health care expenditure, making resource allocation decisions based on cost-utility is viewed by some as being biased against the elderly and disabled. A review of such concerns in the context of analyses of cancer care by the UK NICE cited three potential limitations: 1) insufficient sensitivity of the EQ-5D HRQL instrument to changes in health status of cancer patients, 2) diminished validity of certain assumptions of the time-tradeoff method for estimating the values of various health states for patients at the end of life, and 3) relying on using members of the general population rather than actual cancer patients to estimate the values of various health states (Garau 2011).
Certain cost-per-QALY-gained levels have been cited as informal decision thresholds for acceptance of new interventions (e.g., the equivalent of $50,000 or $100,000 per QALY in the wealthy nations); however, analyses of societal preferences suggest much higher levels of acceptance (Braithwaite 2008). Further, without recognition of any limits to providing all potentially beneficial health technologies to all people, such a threshold for the acceptable cost of a QALY has little relevance (Weinstein 2008). Comparisons of the cost per QALY gained from various health care interventions in widespread use can be revealing about how efficient health care systems are in allocating their resources. A continuously updated, detailed set of standardized cost-utility analyses, including tables of cost-utility ratios for many types of health care interventions, can be found at the Cost-Effectiveness Analysis Registry, maintained by the Tufts Medical Center.
QALYs and other HALYs can enable comparisons among health technologies that have different types of health effects and help to inform resource allocation. Given their relative strengths and weaknesses, these measures are preferable to other measures of health improvement when it is important to make comparisons across diverse interventions. Aside from methodological considerations, their use has been limited by various political and social concerns (Neumann 2010). The relevance of cost-utility analysis for resource allocation depends, at least in part, on how health care is organized and financed.
E. Role of Budget Impact Analysis
Budget-impact analysis determines the impact of implementing or adopting a particular technology or program on a designated budget. The designated budget is generally the responsibility of a particular health care program or authority, e.g., a drug plan or formulary, a hospital, an employer-sponsored health plan, or a regional or national health authority (Mauskopf 2007). It does not necessarily account for the broader economic impact (e.g., societal impact) of implementing or adopting the technology. BIAs can take different forms. For example, a BIA can be conducted simply to determine how much a technology would increase or decrease a particular budget. Or, it could be conducted to determine whether, or to what extent, one or more technologies could be implemented within a fixed (or “capped”) budget. BIAs have appeared with increasing frequency during the past decade, along with greater attention to improvement and standardization of their methods, transparency, and reporting, including with respect to the uses of BIA given decision makers’ various economic perspectives (Orlewska 2009).
A BIA might incorporate a CEA to determine the most cost-effective combination of technologies that can be implemented subject to a budget constraint. However, a CEA is not a substitute for a BIA; indeed, a CEA may yield an inappropriate finding for making budgetary decisions. For example, a CEA of alternative population screening tests might indicate that technology A is the most cost-effective (e.g., in dollars per case of cancer detected). However, allocating resources efficiently (e.g., maximizing cost-effectiveness) may not be consistent with affordability, i.e., remaining within a fixed budget. As such, a fixed budget amount may be too small to implement technology A for the full designated population, forcing the use of an alternative (less cost-effective) technology, no technology, or a policy to limit the use of technology A to fewer people in order to remain within the fixed budget. Box V-11 presents a hypothetical example of a BIA in which a budget constraint is contrary to selecting the most cost-effective alternative. The need for a health program (such as a drug formulary) to operate within a particular budget constraint may be contrary to selecting a technology that is cost-effective or even cost-saving for the broader health care system. This is a form of the “silo budgeting” problem, in that each budget is managed independently of other budgets and of the overall health system. The inability to transfer funds across these silos can undermine system-wide efficiency.
Box V-11. Cost Effectiveness of New Intervention ‘A’ in the Context of a
Fixed Budget:
A Hypothetical Budget Impact Analysis
| Patient subgroup age (years) |
Δ Cost per life- year gained (£/life-yr) |
Net cost of intervention ‘A’ over existing treatment (£/patient) |
Number of patients per year |
Potential budget impact (£/yr) |
|---|---|---|---|---|
| <45 | 200,000 | 500 | 250 | 125,000 |
| 45-60 | 75,000 | 500 | 1,000 | 500,000 |
| 61-75 | 25,000 | 500 | 1,750 | 875,000 |
| <75 | 15,000 | 500 | 2,000 | 1,000,000 |
How should a fixed annual budget of £500,000 be allocated?
It would be most cost-effective to provide Intervention ‘A’ to patients age
>75 years. However, there is insufficient budget to provide the intervention to all patients in that subgroup. Although there is sufficient budget to provide the intervention to all patients age 45-60 years, this is not the most cost-effective approach.
Source: With kind permission from Springer Science+Business Media: Pharmacoeconomics, Developing guidance for budget impact analysis, 19(6), 2001, 609-21, Trueman P, Drummond M, Hutton J, Figure 1, and any original (first) copyright notice displayed with material.
F. Collecting Cost Data in Clinical Studies.
The validity of a cost-related study depends on the sources of the data for costs and outcomes. Increased attention is being given to collection of cost data in more rigorous, prospective studies. The closer integration of economic and clinical studies raises important methodological issues. In order to promote more informed resource allocation for new technologies, it would be desirable to generate reliable cost and outcomes data during the early part of a technology's lifecycle, such as during RCTs required for seeking regulatory approval for marketing. Although an RCT would be expected to yield the most reliable data concerning efficacy of an intervention, the care given in an RCT and the costs of providing it may be atypical compared to more general settings. For example, RCTs may involve more extensive and frequent laboratory tests and other patient monitoring, and may occur more often in academic medical centers whose costs tend to be higher than in community health care institutions. Other aspects of trial design, sample size, choice of outcome measures, identification and tabulation of costs, burden on investigators of data collection and related matters affect the usefulness of clinical trial data for meaningful economic studies (Briggs 2003; Drummond 2005; Graves 2002; Poe 1995). The prevalence of multinational clinical trials of drugs and other technologies can complicate estimating country-specific treatment effects and cost-effectiveness, given differences in epidemiological factors, health care delivery models, resource use, and other factors (Willke 1998).
References for Chapter V
Arnesen T, Nord E. The value of DALY life: problems with ethics and validity of disability adjusted life years. BMJ. 2000;320(7246):1398. Pubmed | PMC free article.
Braithwaite RS, Meltzer DO, King JT Jr, et al. What does the value of modern medicine say about the $50,000 per quality-adjusted life-year decision rule? Med Care. 2008;46(4):349-56. PubMed
Briggs A, Clark T, Wolstenholme J, Clarke P. Missing… presumed at random: cost-analysis of incomplete data. Health Econ. 2003;12(5):377-92. PubMed
Byford S, Palmer S. Common errors and controversies in pharmacoeconomic analyses. Pharmacoeconomics. 1998;13(6):659-66. PubMed
Chapman RH, Berger M, Weinstein MC, Weeks JC, Goldie S, Neumann PJ. When does quality-adjusting life-years matter in cost-effectiveness analysis? Health Econ. 2004;13(5):429-36. PubMed
Disease Control Priorities Project, Using Cost-Effectiveness Analysis for Setting Health Priorities. March 2008. Accessed Oct 1, 2013 at: http://www.dcp2.org/file/150/DCPP-CostEffectiveness.pdf.
Drummond MF, Sculpher MJ, Torrance GW, O’Brien BJ, Stoddart GL. Methods for the Economic Evaluation of Health Care Programmes. Third Edition. Oxford: Oxford University Press; 2005.
Elixhauser A, Halpern M, Schmier J, Luce BR. Health care CBA and CEA from 1991 to 1996: an updated bibliography. Med Care. 1998;36(suppl. 5):MS1-9,MS18-147. PubMed
Eccles M, Mason J. How to develop cost-conscious guidelines. Health Technol Assess. 2001;5(16):1-69. PubMed
Garau M, Shah KK, Mason AR, Wang Q, Towse A, Drummond MF. Using QALYs in cancer: a review of the methodological limitations. Pharmacoeconomics. 2011;29(8):673-85.PubMed
Gerard K, Mooney G. QALY league tables: handle with care. Health Economics. 1993;2(1):59-64. PubMed
Gold MR, Siegel JE, Russell LB, Weinstein MC. Cost-Effectiveness in Health and Medicine. New York, NY: Oxford University Press; 1996.
Graves N, Walker D, Raine R, et al. Cost data for individual patients included in clinical studies: no amount of statistical analysis can compensate for inadequate costing methods. Health Economics. 2002;11(8):735-9. PubMed
Greenberg D, Neumann PJ. Does adjusting for health-related quality of life matter in economic evaluations of cancer-related interventions? Expert Rev Pharmacoecon Outcomes Res. 2011;11(1):113-9.PubMed
Hjelmgren J, Berggren F, Andersson F. Health economic guidelines--similarities, differences and some implications. Value Health. 2001;4(3):225-50.PubMed
Hogness JR,Van Antwerp M. The Artificial Heart: Prototypes, Policies, and Patients. Washington, DC: National Academy Press; 1991. Used with permission from the National Academy of Sciences, courtesy of the National Academies Press, Washington, DC. Pubmed | Bookshelf free book
Husereau D, Drummond M, Petrou S, Carswell C, et al.; CHEERS Task Force. Consolidated Health Economic Evaluation Reporting Standards (CHEERS) statement. Int J Technol Assess Health Care. 2013;29(2):117-22. PubMed
IQWiG (Institute for Quality and Efficiency in Health Care). General Methods for the Assessment of the Relation of Benefits to Costs. Version 1.0 – 19/11/2009. Accesed Aug. 1, 2013 at: https://www.iqwig.de/download/General_Methods_for_the_Assessment_of_the_Relation_of_Benefits_to_Costs.pdf.
Mauskopf JA, Sullivan SD, Annemans L, Caro J, et al. Principles of good practice for budget impact analysis: report of the ISPOR Task Force on good research practices--budget impact analysis. Value Health. 2007;10(5):336-47. PubMed
Maynard A. Developing the health care market. Econ J. 1991;101(408):1277-86.
McGhan WF, Al M, Doshi JA, Kamae I, Marx SE, Rindress D. The ISPOR Good Practices for Quality Improvement of Cost-Effectiveness Research Task Force Report. Value Health. 2009;12(8):1086-99. PubMed
Neuhauser D, Lewicki AM. What do we gain from the sixth stool guaiac? N Engl J Med. 1975;293(5):226-8. PubMed
Neumann PJ, Weinstein MC. Legislating against use of cost-effectiveness information. N Engl J Med 2010;363(16):1495-7. //www.nejm.org/doi/full/10.1056/NEJMp1007168. PubMed
Nixon J, Stoykova B, Glanville J, Christie J, Drummond M, Kleijnen J. The U.K. NHS Economic Evaluation Database. Economic issues in evaluations of health technology. Int J Technol Assess Health Care. 2000; 16(3): 731-42. PubMed
Nord E. The QALY − a measure of social value rather than individual utility? Health Econ. 1994;3(2):89-93. PubMed
Orlewska E, Gulácsi L. Budget-impact analyses: a critical review of published studies. Pharmacoeconomics. 2009;27(10):807-27. PubMed
Poe NR, Griffiths RI. Clinical-economic Trials. In Tools for Evaluating Health Technologies: Five Background Papers. US Congress, Office of Technology Assessment, BP-H-142, 125-49. Washington, DC: US Government Printing Office; 1995. GPO free book.
Rettig RA, Levinsky NG, eds. Kidney Failure and the Federal Government. Washington, DC: National Academy Press; 1991. Publisher free book.
Trueman P, Drummond M, Hutton J. Developing guidance for budget impact analysis. Pharmacoeconomics. 2001;19(6):609-21. PubMed
Ubel PA, Nord E, Gold M, et al. Improving value measurement in cost-effectiveness analysis. Med Care. 2000;38(9):892-901. PubMed
Weinstein MC. How much are Americans willing to pay for a quality-adjusted life year? Med Care. 2008;46(4):343-5. PubMed
Weinstein MC, Stason WB. Foundations of cost-effectiveness analysis for health and medical practices. N Engl J Med. 1977;296(13):716-21. PubMed
Willke RJ, Glick HA, Polsky D, Schulman K. Estimating country-specific cost-effectiveness from multinational clinical trials. Health Econ. 1998;7(6):481-93. PubMed
Wonderling D, Sawyer L, Fenu E, Lovibond K, Laramée P. National Clinical Guideline Centre cost-effectiveness assessment for the National Institute for Health and Clinical Excellence. Ann Intern Med. 2011;154(11):758-65. PubMed
Page 1 of 1
Last Reviewed: January 25, 2021