

HTA 101: IV. INTEGRATIVE METHODS
- A. Systematic Literature Reviews
- B. Working with Best Evidence
- C. Meta-Analysis
- D. Guidelines for Reporting Primary and Secondary Research
- E. Modeling
- F. Assessing the Quality of a Body of Evidence
- G. Consensus Development
- References for Chapter IV
Integrative methods (or secondary or synthesis methods) involve combining data or information from existing sources, including from primary data studies. These can range from quantitative, structured approaches such as meta-analyses or systematic literature reviews to informal, unstructured literature reviews.
Having considered the merits of individual studies, an assessment group must then integrate, synthesize, or consolidate the available relevant findings. For many topics in HTA, there is no single definitive primary study, e.g., that settles whether one technology is better than another for a particular clinical situation. Even where definitive primary studies exist, findings from them may be combined or considered in broader social and economic contexts in order to help inform policies.
- Systematic literature review
- Meta-analysis
- Modeling (e.g., decision trees, state-transition models, infectious disease models)
- Group judgment (“consensus development”)
- Unstructured literature review
- Expert opinion
Certain biases inherent in traditional means of consolidating literature (i.e., non-quantitative or unstructured literature reviews and editorials) are well recognized, and greater emphasis is given to more structured, quantified, and better-documented methods. The body of knowledge concerning how to strengthen and apply these integrative methods has grown substantially. Considerable work has been done to improve the validity of decision analysis and meta-analysis in particular over the last 25 years (see, e.g., Eckman 1992; Eddy 1992; Lau 1992). This was augmented by consensus-building approaches of the NIH Consensus Development Program, the panels on appropriateness of selected medical and surgical procedures conducted by the RAND Corporation, the clinical practice guidelines activities sponsored until the mid-1990s by the predecessor agency to AHRQ (the Agency for Health Care Policy and Research), and others.
Systematic reviews, meta-analyses, and certain types of modeling consolidate findings of existing relevant research in order to resolve inconsistencies or ambiguities among existing studies and yield findings that may not have been apparent or significant in individual studies. These study designs use predetermined criteria and systematic processes to search for, screen for inclusion and exclusion, and combe the findings of existing studies.
Although systematic reviews, meta-analyses, and modeling can produce new insights from existing evidence, they do not generate new data. Well-formulated inclusion and exclusion criteria can help to diminish various sources of bias that could be introduced by the primary data studies or the selection of these studies for the integrative studies.
The applicability of the findings of integrative methods is constrained by any limitations of their component primary studies with respect to, e.g., patient age groups, comorbidities, health care settings, and selection of outcomes measures. Regardless of how rigorously a systematic review is conducted, its ability to determine the most effective intervention is limited by the scope and quality of the underlying evidence. Even studies that satisfy rigorous inclusion criteria may, as a group, reflect publication bias. Other factors may limit the external validity of the findings, such as narrowly defined study populations (e.g., with no comorbidities), inappropriate comparison therapies, insufficient duration of follow-up, and restriction to clinical settings with high levels of expertise and ancillary services that may not prevail in community practice. Often, the greatest value of a systematic review or meta-analysis is its ability to identify gaps in evidence that may be helpful in identifying the need for future primary studies.
Four major types of integrative methods, i.e., systematic literature reviews, meta-analysis, decision analysis, and consensus development, are described below.
A. Systematic Literature Reviews
A systematic literature review is a form of structured literature review that addresses one or more evidence questions (or key questions) that are formulated to be answered by analysis of evidence. Broadly, this involves:
- Objective means of searching the literature
- Applying predetermined inclusion and exclusion criteria to this literature
- Critically appraising the relevant literature
- Extraction and synthesis of data from evidence base to formulate answers to key questions
Depending on the purpose of the systematic review and the quality of the included studies, systematic reviews often include meta-analyses. A useful way to define the key questions used in a systematic review and to guide the literature search is the “PICOTS” format (see, e.g., Counsell 1997):
- Population: e.g., condition, disease severity/stage, comorbidities, risk factors, demographics
- Intervention: e.g., technology type, regimen/dosage/frequency, technique/method of administration
- Comparator: e.g., placebo, usual/standard care, active control
- Outcomes: e.g., morbidity, mortality, quality of life, adverse events
- Timing: e.g., duration/intervals of follow-up
- Setting: e.g., primary, inpatient, specialty, home care
Not all evidence questions use all of these elements; some use PICO only.
The main steps of a systematic review include the following (see, e.g., Buckley 2014; Rew 2011; Shea 2007; Sutton 1998):
- Specify purpose of the systematic review
- Specify evidence questions. Use appropriate structured format, e.g., PICOTS
- Specify review protocol that is explicit, unbiased, and reproducible, including:
- Inclusion and exclusion criteria for studies to be reviewed, including type/status of publication (e.g., peer-reviewed publication vs. grey literature)
- Bibliographic databases (and other sources, if applicable) to be searched
- Search terms/logic for each database
- Methods of review (e.g., number of independent parallel reviewers of each study)
- Intention to conduct meta-analysis (if appropriate and feasible) and specification of methods to combine/pool data
- Register or publish protocol, as appropriate
- Perform comprehensive literature search
- Document all search sources and methods
- Review search results and compare to inclusion/exclusion criteria
- Account for included and excluded studies (e.g., using a flow diagram)
- Identify and exclude duplicate studies, as appropriate
- Compile and provide lists of included studies and excluded studies (with reasons for exclusion)
- Assess potential sources of publication bias
- Systematically extract data from each included study
- Consistent with review protocol
- Include PICOTS characteristics
- Present extracted data in tabular form
- Assess quality of individual studies retrieved/reviewed
- Document quality for each study
- Account for potential conflicts of interest
- Perform meta-analysis (if specified in protocol and if methodologically feasible based on primary data characteristics)
- Assess quality (or strength) of cumulative body of evidence
- Assess risks of bias, directness or relevance of evidence (patients, interventions, outcomes, etc.) to the evidence questions, consistency of findings across available evidence, and precision in reporting results
- Assign grade to cumulative body of evidence
- Present results/findings
- Link results/findings explicitly to evidence from included studies
- Account for quality of the included studies
- Present clearly to enable critical appraisal and replication of systematic review
- Conduct sensitivity analysis of review results
- Examine the impact on review results of inclusion/exclusion criteria, publication bias, and plausible variations in assumptions and estimates of outcomes and other parameters
- Also conduct analyses (e.g., subgroup analyses and meta-regression) for better understanding of heterogeneity of effects
- Describe limitations and actual/potential conflicts of interest and biases in the process
- Account for body of included studies and the systematic review process
- Describe evidence gaps and future research agenda, as appropriate
- Disseminate (e.g., publish) results
Assessing the quality of individual studies is described in chapter III. Assessing the quality (or strength) of a cumulative body of evidence is described later in chapter IV. Dissemination of results is described in chapter VIII.
In conducting literature searches for systematic reviews, a more comprehensive and unbiased identification of relevant clinical trials and other studies (consistent with the inclusion criteria) may be realized by expanding the search beyond the major biomedical bibliographic databases such PubMed and Embase. Additional in-scope studies may be identified via specialized databases and clinical trial registries, reference lists, hand-searching of journals, conference abstracts, contacting authors and trials sponsors (e.g., life sciences companies) to find unpublished trials, and Internet search engines. The studies identified in these ways should remain subject to the quality criteria used for the systematic review. The extent to which an expanded search has an impact on the findings of the systematic review varies (Savoie 2003). Systematic reviews of particular types of technologies may use different sets of databases and synthesis approaches for particular types of technologies, such as for imaging procedures and diagnostic tests (Bayliss 2008; Whiting 2008).
One of the tools developed to assess the quality of systematic reviews, the Assessment of Multiple Systematic Reviews (AMSTAR), which was derived using nominal group technique and factor analysis of previous instruments, has the following 11 items (Shea 2007; Shea 2009):
- Was an ‘a priori’ design provided?
- Was there duplicate study selection and data extraction?
- Was a comprehensive literature search performed?
- Was the status of publication ([e.g.,] grey literature) used as an inclusion criterion?
- Was a list of studies (included and excluded) provided?
- Were the characteristics of the included studies provided?
- Was the scientific quality of the included studies assessed and documented?
- Was the scientific quality of the included studies used appropriately in formulating conclusions?
- Were the methods used to combine the findings of studies appropriate?
- Was the likelihood of publication bias assessed?
- Was the conflict of interest stated?
In addition to those for assessing methodological quality of systematic reviews, there are instruments to assess the reporting of systematic reviews and meta-analyses, including the Preferred Reporting Items of Systematic reviews and Meta-Analyses instrument (PRISMA) (Moher 2009), as shown in Box 1. Various computer software packages are available to manage references and related bibliographic information for conducting systematic reviews; examples are EndNote, Reference Manager, and RefWorks (see, e.g., Hernandez 2008), though no particular recommendation is offered here.
Box 1. PRIMSA Checklist of Items to Include When Reporting a Systematic Review
| Section/topic | # | Checklist item | Reported on page # |
| TITLE | |||
| Title | 1 | Identify the report as a systematic review, meta-analysis, or both. | |
| ABSTRACT | |||
| Structured summary | 2 | Provide a structured summary including, as applicable: background; objectives; data sources; study eligibility criteria, participants, and interventions; study appraisal and synthesis methods; results; limitations; conclusions and implications of key findings; systematic review registration number. | |
| INTRODUCTION | |||
| Rationale | 3 | Describe the rationale for the review in the context of what is already known. | |
| Objectives | 4 | Provide an explicit statement of questions being addressed with reference to participants, interventions, comparisons, outcomes, and study design (PICOS). | |
| METHODS | |||
| Protocol and registration | 5 | Indicate if a review protocol exists, if and where it can be accessed (e.g., Web address), and, if available, provide registration information including registration number. | |
| Eligibility criteria | 6 | Specify study characteristics (e.g., PICOS, length of follow-up) and report characteristics (e.g., years considered, language, publication status) used as criteria for eligibility, giving rationale. | |
| Information sources | 7 | Describe all information sources (e.g., databases with dates of coverage, contact with study authors to identify additional studies) in the search and date last searched. | |
| Search | 8 | Present full electronic search strategy for at least one database, including any limits used, such that it could be repeated. | |
| Study selection | 9 | State the process for selecting studies (i.e., screening, eligibility, included in systematic review, and, if applicable, included in the meta-analysis). | |
| Data collection process | 10 | Describe method of data extraction from reports (e.g., piloted forms, independently, in duplicate) and any processes for obtaining and confirming data from investigators. | |
| Data items | 11 | List and define all variables for which data were sought (e.g., PICOS, funding sources) and any assumptions and simplifications made. | |
| Risk of bias in individual studies | 12 | Describe methods used for assessing risk of bias of individual studies (including specification of whether this was done at the study or outcome level), and how this information is to be used in any data synthesis. | |
| Summary measures | 13 | State the principal summary measures (e.g., risk ratio, difference in means). | |
| Synthesis of results | 14 | Describe the methods of handling data and combining results of studies, if done, including measures of consistency (e.g., I2) for each meta-analysis. | |
Source: Moher D, Liberati A, Tetzlaff J, Altman DG, The PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009;6(7):e1000097.
Box IV-1. PRIMSA Checklist of Items to Include When Reporting a Systematic Review (cont’d)
| Section/topic | # | Checklist item | Reported on page # |
| Risk of bias across studies | 15 | Specify any assessment of risk of bias that may affect the cumulative evidence (e.g., publication bias, selective reporting within studies). | |
| Additional analyses | 16 | Describe methods of additional analyses (e.g., sensitivity or subgroup analyses, meta-regression), if done, indicating which were pre-specified. | |
| RESULTS | |||
| Study selection | 17 | Give numbers of studies screened, assessed for eligibility, and included in the review, with reasons for exclusions at each stage, ideally with a flow diagram. | |
| Study characteristics | 18 | For each study, present characteristics for which data were extracted (e.g., study size, PICOS, follow-up period) and provide the citations. | |
| Risk of bias within studies | 19 | Present data on risk of bias of each study and, if available, any outcome level assessment (see item 12). | |
| Results of individual studies | 20 | For all outcomes considered (benefits or harms), present, for each study: (a) simple summary data for each intervention group (b) effect estimates and confidence intervals, ideally with a forest plot. | |
| Synthesis of results | 21 | Present results of each meta-analysis done, including confidence intervals and measures of consistency. | |
| Risk of bias across studies | 22 | Present results of any assessment of risk of bias across studies (see Item 15). | |
| Additional analysis | 23 | Give results of additional analyses, if done (e.g., sensitivity or subgroup analyses, meta-regression [see Item 16]). | |
| DISCUSSION | |||
| Summary of evidence | 24 | Summarize the main findings including the strength of evidence for each main outcome; consider their relevance to key groups (e.g., healthcare providers, users, and policy makers). | |
| Limitations | 25 | Discuss limitations at study and outcome level (e.g., risk of bias), and at review-level (e.g., incomplete retrieval of identified research, reporting bias). | |
| Conclusions | 26 | Provide a general interpretation of the results in the context of other evidence, and implications for future research. | |
| FUNDING | |||
| Funding | 27 | Describe sources of funding for the systematic review and other support (e.g., supply of data); role of funders for the systematic review. |
Source: Moher D, Liberati A, Tetzlaff J, Altman DG, The PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009;6(7):e1000097.
A resource for minimizing publishing bias in systematic reviews is PROSPERO, an international database of prospectively registered systematic reviews in health and social care. The main objectives of PROSPERO are to reduce unplanned duplication of systematic reviews and provide transparency in the review process with the aim of minimizing reporting/publication bias. By providing a comprehensive listing of systematic reviews and their protocols at their inception, PROSPERO is intended to help counter publication bias by providing a permanent record of the original protocol of each systematic review, whether or not it is published. As such, comparison of this record to any reported findings of the systematic reviews can reveal any differences between the methods and outcomes of the registered protocol with those that are ultimately reported. Also, registration of reviews should diminish instances of duplication of effort. Established in 2011, PROSPERO is managed by the Centre for Reviews and Dissemination and funded by the UK National Institute for Health Research (Booth 2012).
B. Working with Best Evidence
In health care as well as other fields, there are tradeoffs between wanting to rely on the highest quality of evidence and the need to derive useful findings when evidence of the highest quality is limited or unavailable. For example:
In law, there is a principle that the same evidence that would be essential in one case might be disregarded in another because in the second case there is better evidence available…. Best-evidence synthesis extends this principle to the practice of research review. For example, if a literature contains several studies high in internal and external validity, then lower quality studies might be largely excluded from the review …. However, if a set of studies high in internal and external validity does not exist, we might cautiously examine the less well designed studies to see if there is adequate unbiased information to come to any conclusion (Slavin 1995).
A desire to base health care decisions and policies on evidence generated from study designs that are of high quality for establishing internal validity of a causal relationship should not preclude using the best evidence that is available from other study designs. First, as described in detail in chapter III, evidence of internal validity should be complemented by evidence of external validity wherever appropriate and feasible to demonstrate that a technology works in real-world practice. Second, whether for internal validity or external validity, evidence from the highest quality study designs may not be available. For purposes of helping to inform clinical decisions and health care policies, it may be impractical to cease an evidence review because of the absence of high-quality evidence. The “best evidence” may be the best available evidence, i.e., the best evidence that is currently available and relevant for the evidence questions of interest (Ogilvie 2005).
“Best evidence” is not based on a single evidence hierarchy and it is not confined to internal validity. Even where traditional high-quality evidence with internal validity does exist (e.g., based on well-designed and conducted RCTs or meta-analyses of these), complementary evidence from other study designs (e.g., practical clinical trials, observational studies using registry data) may be needed to determine external validity. Where there is little or no high-quality evidence with internal validity, it may be necessary to pursue lower quality evidence for internal validity, such as non-randomized clinical trials, trials using historical controls, case series, or various types of observational studies, while documenting potential forms of bias that might accompany such evidence.
The need to seek lower-quality evidence in the absence of high-quality evidence also depends on the nature of the health problem and evidence question(s) of interest. For example, given a serious health problem for which one or more existing technologies have been proven safe and effective based on high-quality evidence, the evidence required for a new technology should be based on high-quality evidence, as substitution of an existing proven technology by a new one with poorly established safety and uncertain effectiveness could pose unacceptable risks to patients who are experiencing good outcomes. In the instance of a rare, serious health problem for which no effective treatment exists, it may be difficult to conduct adequately powered RCTs, and lower-quality evidence suggesting a clinically significant health benefit, even with limited data on safety, may be acceptable as the best available evidence. Of course, appraising the evidence and assigning grades to any accompanying recommendations must remain objective and transparent. That is, just because an assessment must rely on the best available evidence does not necessarily mean that this evidence is high-quality (e.g., “Level I”) evidence, or that recommendations based on it will be “Strong” or of “Grade A.”
Inclusion and exclusion criteria for a systematic review should be informed by the evidence questions to be addressed as well as some knowledge about the types and amounts of evidence available, which can be determined from examining previous reviews and a preliminary literature search. To the extent that there appears to be a body of high-quality evidence with high internal and external validity, it may be unnecessary to pursue evidence of lower quality. However, in the absence of such evidence, it may be necessary to pursue lower-quality evidence (Lyles 2007; Ogilvie 2005).
C. Meta-Analysis
Meta-analysis refers to a group of statistical methods for combining (or “pooling”) the data or results of multiple studies to obtain a quantitative estimate of the overall effect of a particular technology (or other variable) on a defined outcome. This combination may produce a stronger conclusion than can be provided by any individual study (Laird 1990; Normand 1999; Thacker 1988). A meta-analyses is not the same as a systematic review, although many systematic reviews include meta-analyses, where doing so is methodologically feasible.
The purposes of meta-analysis include:
- Encourage systematic organization of evidence
- Increase statistical power for primary end points
- Increase general applicability (external validity) of findings
- Resolve uncertainty when reports disagree
- Assess the amount of variability among studies
- Provide quantitative estimates of effects (e.g., odds ratios or effect sizes)
- Identify study characteristics associated with particularly effective treatments
- Call attention to strengths and weaknesses of a body of research in a particular area
- Identify needs for new primary data collection
Meta-analysis typically is used for topics that have no definitive studies, including topics for which non-definitive studies are in some disagreement. Evidence collected for HTA often includes studies with insufficient statistical power (e.g., because of small sample sizes) to detect any true treatment effects. By combining the results of multiple studies, a meta-analysis may have sufficient statistical power to detect a true treatment effect if one exists, or at least narrow the confidence interval around the mean treatment effect.
The basic steps in meta-analysis are the following:
- Specify the problem of interest.
- Specify the criteria for inclusion and exclusion of studies (e.g., type and quality).
- Identify and acquire all studies that meet inclusion criteria.
- Classify study characteristics and findings according to, e.g.: study characteristics (patient types, practice setting, etc.), methodological characteristics (e.g., sample sizes, measurement process), primary results and type of derived summary statistics.
- Statistically combine study findings using common units (e.g., by averaging effect sizes); relate these to study characteristics; perform sensitivity analysis.
- Present results.
Meta-analysis can be limited by publication bias of the RCTs or other primary studies used, biased selection of available relevant studies, poor quality of the primary studies, unexplainable heterogeneity (or otherwise insufficient comparability) in the primary studies, and biased interpretation of findings (Borenstein 2009; Nordmann 2012). The results of meta-analyses that are based on sets of RCTs with lower methodological quality have been reported to show greater treatment effects (i.e., greater efficacy of interventions) than those based on sets of RCTs of higher methodological quality (Moher 1998). However, it is not apparent that any individual quality measures are associated with the magnitude of treatment effects in meta-analyses of RCTs (Balk 2002).
Some of the techniques used in the statistical combination of study findings in meta-analysis are: pooling, effect size, variance weighting, Mantel-Haenszel, Peto, DerSimonian and Laird, and confidence profile method. The suitability of any of these techniques for a group of studies depends on the comparability of the circumstances of the individual studies, type of outcome variables used, assumptions about the uniformity of treatment effects, and other factors (Eddy 1992; Laird 1990; Normand 1999). The different techniques of meta-analysis have specific rules about whether or not to include certain types of studies and how to combine their results. Some meta-analytic techniques adjust the results of the individual studies to try to account for differences in study design and related biases to their internal and external validity. Special computational tools may be required to make the appropriate adjustments for the various types of biases in a systematic way (Detsky 1992; Moher 1999; van Houwelingen 2002).
The shortcomings of meta-analyses, which are shared by—though are generally greater in—unstructured literature reviews and other less rigorous synthesis methods, can be minimized by maintaining a systematic approach. Performing meta-analyses as part of high-quality systematic reviews, i.e., that have objective means of searching the literature and apply predetermined inclusion and exclusion criteria to the primary studies used, can diminish the impact of these shortcomings on the findings of meta-analyses (Egger, Smith, Sterne 2001). Compared to the less rigorous methods of combining evidence, meta-analysis can be time-consuming and requires greater statistical and methodologic skills. However, meta-analysis is a much more explicit and accurate method.
Box IV-2. Meta-Analysis: Clinical Trials of Intravenous Streptokinase for Acute Myocardial Infarction

The conventional meta-analysis at left depicts observed treatment effects (odds ratios) and confidence intervals of the 33 individual studies, most of which involved few patients. Although most trials favored streptokinase, the 95 percent confidence intervals of most trials included odds ratios of 1.0 (indicating no difference between treatment with streptokinase and the control intervention). Several studies favored the control treatment, although all of their confidence intervals included odds ratios of 1.0. As shown at the bottom, this meta-analysis pooled the data from all 33 studies (involving a total of 36,974 patients) and detected an overall treatment effect favoring streptokinase, with a narrow 95 percent confidence interval that fell below the 1.0 odds ratio, and P less than 0.001. (P values less than 0.05 or 0.01 are generally accepted as statistically significant.)
The graph at right depicts a "cumulative" meta-analysis in which a new meta-analysis is performed with the chronological addition of each trial. As early as 1971, when available studies might have appeared to be inconclusive and contradictory, a meta-analysis involving only four trials and 962 patients would have indicated a statistically significant treatment effect favoring streptokinase (note 95% confidence interval and P<0.05). By 1973, after eight trials and 2,432 patients, P would have been less than 0.01. By 1977, the P value would have been less than 0.001, after which the subsequent trials had little or no effect on the results establishing the efficacy of streptokinase in saving lives. This approach indicates that streptokinase could have been shown to be lifesaving two decades ago, long before FDA approval was sought and it was adopted into routine practice.
From Lau J, Antman EM, Jiminez-Silva J, Kupelnick B, Mosteller F, Chalmers TC. Cumulative meta-analysis of therapeutic trials for myocardial infarction. N Engl J Med, 327:248-54. Copyright © (1992) Massachusetts Medical Society. Reprinted with permission from Massachusetts Medical Society.
Box IV-2 shows two types of meta-analysis side-by-side: a conventional meta-analysis and a cumulative meta-analysis of the impact of thrombolytic therapy (to dissolve blood clots) on mortality among patients with myocardial infarction. These meta-analyses are applied to the same set of 33 clinical trials reported over a 30-year period. Most of these trials had tens or hundreds of patients, though two were much larger. The “forest plot” diagram on the left represents a single conventional meta-analysis of those 33 trials. Across the sum of nearly 37,000 patients in the 33 trials, that meta-analysis yielded a statistically significant treatment effect favoring the use of streptokinase. The forest plot on the right depicts a cumulative meta-analysis in which iterative meta-analyses could have been performed each time a report of a new trial appeared. The cumulative meta-analysis suggests that a statistically significant treatment effect of streptokinase on morality could have been discerned many years earlier than the appearance of the last of the 33 trials.
Network meta-analysis (also known as multiple-treatment or mixed-treatment comparisons meta-analysis), is used to compare various alternative interventions of interest when there are limited or no available direct (“head-to-head”) trials of those interventions. It enables integration of data from available direct trials and from indirect comparisons, i.e., when the alternative interventions are compared based on trials of how effective they are versus a common comparator intervention (Caldwell 2005; Jansen 2011).
Although meta-analysis has been applied primarily for treatments, meta-analytic techniques also are applied to diagnostic technologies. As in other applications of meta-analysis, the usefulness of these techniques for diagnostic test accuracy is subject to publication bias and the quality of primary studies of diagnostic test accuracy (Deeks 2001; Hasselblad 1995; Irwig 1994; Littenberg 1993). Although meta-analysis is often applied to RCTs, it may be used for observational studies as well (Stroup 2000).
More advanced meta-analytic techniques can be applied to assessing health technologies, e.g., involving multivariate treatment effects, meta-regression, and Bayesian methods (see, e.g., van Houwelingen 2002). Meta-regression refers to techniques for relating the magnitude of an effect to one or more characteristics of the studies used in a meta-analysis, such as patient characteristics, drug dose, duration of study, and year of publication (Thompson 2002).
Various computer software packages are available to help conduct meta-analyses; examples are Comprehensive Meta-analysis (CMA), OpenMeta[Analyst], and RevMan, though no particular recommendation is offered here.
D. Guidelines for Reporting Primary and Secondary Research
The conduct of systematic reviews, meta-analysis, and related integrative studies requires systematic examination of the reports of primary data studies as well as other integrative methods. As integrative methods have taken on more central roles in HTA and other forms of evaluation, methodological standards for conducting and reporting these studies have risen (Egger, Smith, Altman 2001; Moher 1999; Petitti 2001; Stroup 2000). In addition to the PRISMA instrument for systematic reviews and meta-analyses noted above, there are other instruments for assessing the reporting of clinical trials, systematic reviews, meta-analyses of trials, meta-analyses of observational studies, and economic analyses. Some of these are listed in Box IV-3. HTA programs that use the inclusion/exclusion rules and other aspects of these instruments are more likely to conduct more thorough and credible assessments. In addition to their primary purpose of improving reporting of research, these guidelines are helpful forplanning studies of these types and in reviewing studies as part of systematic reviews and other integrative methods. See also Research Reporting Guidelines and Initiatives compiled by the US NLM at: //www.nlm.nih.gov/services/research_report_guide.html.
Box IV-3. Guidelines for Reporting Research
- AMSTAR (Assessment of Multiple Systematic Reviews) (Shea 2009)
- CHEERS (Consolidated Health Economic Evaluation Reporting Standards) (Husereau 2013)
- CONSORT (Consolidated Standards of Reporting Trials) (Turner 2012)
- GRACE (Good ReseArch for Comparative Effectiveness) (Dreyer 2014)
- MOOSE (Meta-analysis of Observational Studies in Epidemiology) (Stroup 2000)
- PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) (Moher 2009)
- QUOROM (Quality Of Reporting Of Meta-analyses) (Moher 1999)
- STARD (Standards for Reporting of Diagnostic Accuracy) (Bossuyt 2003)
- STROBE (Strengthening the Reporting of OBservational Studies in Epidemiology) (von Elm 2008)
- TREND (Transparent Reporting of Evaluations with Nonrandomized Designs) (Des Jarlais 2004)
E. Modeling
Quantitative modeling is used to evaluate the clinical and economic effects of health care interventions. Models are often used to answer “What if?” questions. That is, they are used to represent (or simulate) health care processes or decisions and their impacts under conditions of uncertainty, such as in the absence of actual data or when it is not possible to collect data on all potential conditions, decisions, and outcomes of interest. For example, decision analytic modeling can be used to represent alternative sequences of clinical decisions for a given health problem and their expected health outcomes and cost effectiveness.
The high cost and long duration of large RCTs and other clinical studies also contribute to the interest in developing alternative methods to collect, integrate, and analyze data to answer questions about the impacts of alternative health care interventions. Indeed, some advanced types of modeling are being used to simulate (and substitute in certain ways for) clinical trials.
By making informed adjustments or projections of existing primary data, modeling can help account for patient conditions, treatment effects, and costs that are not present in primary data. This may include adjusting efficacy findings to estimates of effectiveness, and projecting future costs and outcomes.
Among the main types of techniques used in quantitative modeling are decision analysis; state-transition modeling, including Markov modeling (described below) and Monte Carlo simulation; survival and hazard functions; and fuzzy logic. A Monte Carlo simulation uses sampling from random number sequences to assign estimates to parameters with multiple possible values, e.g., certain patient characteristics (Caro 2002; Gazelle 2003; Siebert 2012). Infectious disease modeling is used to understand the spread, incidence, and prevalence of disease, including modeling those that model the impact health care interventions such as immunizations (Bauch 2010) and insect control (Luz 2011).
Decision analysis uses available quantitative estimates to represent (model or simulate) alternative strategies (e.g., of diagnosis and/or treatment) in terms of the probabilities that certain events and outcomes will occur and the values of the outcomes that would result from each strategy (Pauker 1987; Thornton 1992). As described by Rawlins:
Combining evidence derived from a range of study designs is a feature of decision-analytic modelling as well as in the emerging fields of teleoanalysis and patient preference trials. Decision-analytic modelling is at the heart of health economic analysis. It involves synthesising evidence from sources that include RCTs, observational studies, case registries, public health statistics, preference surveys and (at least in the US) insurance claim databases (Rawlins 2008).
Decision models often are shown in the form of "decision trees" with branching steps and outcomes with their associated probabilities and values. Various software programs may be used in designing and conducting decision analyses, accounting for differing complexity of the strategies, extent of sensitivity analysis, and other quantitative factors.
Decision models can be used in different ways. They can be used to predict the distribution of outcomes for patient populations and associated costs of care. They can be used as a tool to support development of clinical practice guidelines for specific health problems. For individual patients, decision models can be used to relate the likelihood of potential outcomes of alternative clinical strategies (such as a decision to undergo a screening test or to select among alternative therapies) or to identify the clinical strategy that has the greatest utility (preference) for a patient. Decision models are also used to set priorities for HTA (Sassi 2003).
Although decision analyses can take different forms, the basic steps of a typical approach are:
- Develop a model (e.g., a decision tree) that depicts the set of important choices (or decisions) and potential outcomes of these choices. For treatment choices, the outcomes may be health outcomes (health states); for diagnostic choices, the outcomes may be test results (e.g., positive or negative).
- Assign estimates (based on available literature) of the probabilities (or magnitudes) of each potential outcome given its antecedent choices.
- Assign estimates of the value of each outcome to reflect its utility or desirability (e.g., using a HRQL measure or QALYs).
- Calculate the expected value of the outcomes associated with the particular choice(s) leading to those outcomes. This is typically done by multiplying the set of outcome probabilities by the value of each outcome.
- Identify the choice(s) associated with the greatest expected value. Based on the assumptions of the decision model, this is the most desirable choice, as it provides the highest expected value given the probability and value of its outcomes.
- Conduct a sensitivity analysis of the model to determine if plausible variations in the estimates of probabilities of outcomes or utilities change the relative desirability of the choices. (Sensitivity analysis is used because the estimates of key variables in the model may be subject to random variation or based on limited data or simply expert conjecture.)
Box IV-4 shows a decision tree for determining the cost of treatment for alternative drug therapies for a given health problem.
Box IV-4. Decision Analysis Model: Cost per Treatment, DrugEx vs. Drug Why

| Treatment | Path | Cum. Cost |
Cum. Prob. |
Weighted Avg. Cost |
Expected Avg. Cost/Treatment |
|---|---|---|---|---|---|
| DrugEx | 1 | $1,500 | 0.09 | $135.00 | |
| 2 | 6,500 | 0.01 | 65.00 | ||
| 3 | 1,000 | 0.81 | 810.00 | ||
| 4 | 6,000 | 0.09 | 540.00 | ||
| Total | 1.00 | NA | $1,550 |
| Treatment | Path | Cum. Cost |
Cum. Prob. |
Weighted Avg. Cost |
Expected Avg. Cost/Treatment |
|---|---|---|---|---|---|
| DrugWhy | 1 | $2,500 | 0.0475 | $118.75 | |
| 2 | 7,500 | 0.0025 | 18.75 | ||
| 3 | 2,000 | 0.9025 | 1,805.00 | ||
| 4 | 7,000 | 0.0475 | 332.50 | ||
| Total | 1.00 | $2,275 |
This decision analysis model compares the average cost per treatment of two drugs for a given patient population. The cost of the new DrugWhy is twice that of DrugEx, the current standard of care. However, the probability (Pr) that using DrugWhy will be associated with an adverse health event, with its own costs, is half of the probability of that adverse event associated with using DrugEx. Also, the response rate of patients (i.e., the percentage of patients for whom the drug is effective) for DrugWhy is slightly higher than that of DrugEx. For patients in whom either drug fails, there is a substantial cost of treatment with other interventions. The model assumes that: the drugs are equally effective when patients respond to them; the cost of an adverse effect associated with either drug is the same; and the cost of treating a failure of either drug is the same. For each drug, there are four potential paths of treatment and associated costs, accounting for whether or not there is an adverse effect and whether or not patients respond to the drug. The model calculates an average cost per treatment of using each drug.
A limitation of modeling with decision trees is representing recurrent health states (i.e., complications or stages of a chronic disease that may come and go, such as in multiple sclerosis). In those instances, a preferable alternative approach is to use state-transition modeling (Siebert 2012), such as in the form of Markov modeling, that use probabilities of moving from one state of health to another, including remaining in a given state or returning to it after intervening health states.
A Markov model (or chain) is a way to represent and quantify changes from one state of health to another, such as different stages of disease and death. These changes can result from the natural history of a disease or from use of health technologies. These models are especially useful for representing patient or population experience when the health problem of interest involves risks that are continuous over time, when the timing of health states is important, and when some or all these health states may recur. Markov models assume that each patient is always in one of a set of mutually exclusive and exhaustive health states, with a set of allowable (i.e., non-zero) probabilities of moving from one health state to another, including remaining in the same state. These states might include normal, asymptomatic disease, one or more stages of progressive disease, and death. For example, in cardiovascular disease, these might include normal, unstable angina, myocardial infarction, stroke, cardiovascular death, and death from other causes. Patient utilities and costs also can be assigned to each health state or event. In representing recurring health states, time dependence of the probabilities of moving among health states, and patient utility and costs for those health states, Markov models enable modeling the consequences or impacts of health technologies (Sonnenberg 1993). Box IV-5 shows a Markov chain for transitions among disease states for the natural history of cervical cancer.
Box IV-5. Disease States and Allowed Transitions for the Natural History Component of a Markov Model Used in a Decision Analysis of Cervical Cancer Screening
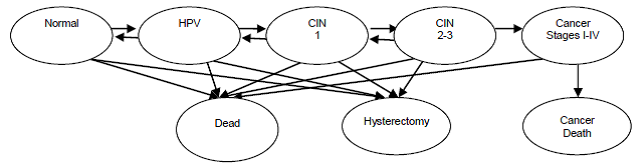
HPV: human papillomavirus; CIN: cervical intraepithelial neoplasia (grades 1, 2, 3)
Transition probabilities among disease states are not shown here.
Source: Kulasingam SL, Havrilesky L, Ghebre R, Myers ER. Screening for Cervical Cancer: A Decision Analysis for the U.S. Preventive Services Task Force. AHRQ Pub. No. 11-05157-EF-1. Rockville, MD: Agency for Healthcare Research and Quality; May 2011.
High-power computing technology, higher mathematics, and large data systems are being used for simulations of clinical trials and other advanced applications. A prominent example is the Archimedes model, a large-scale simulation system that models human physiology, disease, and health care systems. The Archimedes model uses information about anatomy and physiology; data from clinical trials, observational studies, and retrospective studies; and hundreds of equations. In more than 15 diseases and conditions, it models metabolic pathways, onset and progression of diseases, signs and symptoms of disease, health care tests and treatments, health outcomes, health services utilization, and costs. In diabetes, for example, the Archimedes model has been used to predict the risk of developing diabetes in individuals (Stern 2008), determine the cost-effectiveness of alternative screening strategies to detect new cases of diabetes (Kahn 2010), and simulate clinical trials of treatments for diabetes (Eddy 2003).
One of the challenges of decision analysis is accounting for the varying perspectives of stakeholders in a given decision, including what attributes or criteria (e.g., health benefit, avoidance of adverse events, impact on quality of life, patient copayment) are important to each stakeholder and the relative importance or weight of each attribute. Multi-criteria decision analysis (MCDA) has been applied to HTA (Goetghebeur 2012; Thokala 2012). A form of operations research, MCDA is a group of methods for identifying and comparing the attributes of alternatives (e.g., therapeutic options) from the perspectives of multiple stakeholders. It evaluates these alternatives by ranking, rating, or pairwise comparisons, using such stakeholder elicitation techniques as conjoint analysis and analytic hierarchy process.
Models and their results are only aids to decision making; they are not statements of scientific, clinical, or economic fact. The report of any modeling study should carefully explain and document the assumptions, data sources, techniques, and software. Modelers should make clear that the findings of a model are conditional upon these components. The use of decision modeling in cost-effectiveness analysis in particular has advanced in recent years, with development of checklists and standards for these applications (see, e.g., Gold 1996; Philips 2004; Soto 2002; Weinstein 2003).
Assumptions and estimates of variables used in models should be validated against actual data as such data become available, and the models should be modified accordingly. Modeling should incorporate sensitivity analyses to quantify the conditional relationships between model inputs and outputs.
Various computer software packages are available to conduct decision-analytic and other forms of modeling; examples are Decision Analysis, Excel, and TreeAge; no particular recommendation is offered here.
F. Assessing the Quality of a Body of Evidence
Systematic reviews assemble bodies of evidence pertaining to particular evidence questions. Although each body of evidence may comprise studies of one type, e.g., RCTs, they may also comprise studies of multiple designs. Many approaches have been used to assess the quality of a body of evidence since the 1970s. In recent years, there has been some convergence in these approaches, including by such organizations as the Grading of Recommendations Assessment, Development and Evaluation (GRADE) Working Group (Balshem 2011), the Cochrane Collaboration (Higgins 2011), the US Agency for Healthcare Research and Quality Evidence-based Practice Centers (AHRQ EPCs) (Berkman 2014), the Oxford Centre for Evidence-Based Medicine (OCEBM Levels of Evidence Working Group 2011), and the US Preventive Services Task Force (USPSTF) (US Preventive Services Task Force 2008). According to the GRADE Working Group, more than 70 organizations, including international collaborations, HTA agencies, public health agencies, medical professional societies, and others have endorsed GRADE and are using it or modified versions of it (GRADE Working Group 2013).
Increasingly, organizations such as those noted above consider the following types of factors, dimensions, or domains when assessing the quality of a body of evidence:
- Risk of bias
- Precision
- Consistency
- Directness
- Publication (or reporting) bias
- Magnitude of effect size (or treatment effect)
- Presence of confounders that would diminish an observed effect
- Dose-response effect (or gradient)
Risk of bias refers to threats to internal validity, i.e., limitations in the design and implementation of studies that may cause some systematic deviation in an observation from the true nature of an event, such the deviation of an observed treatment effect from the true treatment effect. For a body of evidence, this refers to bias in the overall or cumulative observed treatment effect of the group of relevant studies, for example, as would be derived in a meta-analysis. As described in chapter III regarding the quality of individual studies, the quality of a body of evidence is subject to various types of bias across its individual studies. Among these are selection bias (including lack of allocation concealment), performance bias (including insufficient blinding of patients and investigators), attrition bias, and detection bias. Some quality rating schemes for bodies of evidence compile aggregate ratings of the risk of bias in individual studies.
Precision refers to the extent to which a measurement, such as the mean estimate of a treatment effect, is derived from a set of observations having small variation (i.e., are close in magnitude to each other). Precision is inversely related to random error. Small sample sizes and few observations generally widen the confidence interval around an estimate of an effect, decreasing the precision of that estimate and lowering any rating of the quality of the evidence. Due to potential sources of bias that may increase or decrease the observed magnitude of a treatment effect, a precise estimate is not necessarily an accurate one. As noted in chapter III, some researchers contend that if individual studies are to be assembled into a body of evidence for a systematic review, precision should be evaluated not at the level of individual studies, but when assessing the quality of the body of evidence. This is intended to avoid double-counting limitations in precision from the same source (Viswanathan 2014).
Consistency refers to the extent that the results of studies in a body of evidence are in agreement. Consistency can be assessed based on the direction of an effect, i.e., whether they are on the positive or negative side of no effect or the magnitudes of effect sizes across the studies are similar. One indication of consistency across studies in a body of evidence is overlap of their respective confidence intervals around an effect size. Investigators should seek to explain inconsistency (or heterogeneity) of results. For example, inconsistent results may arise from a body of evidence with studies of different populations or different doses or intensity of a treatment. Plausible explanations of these inconsistent results may include that, in similar patient populations, a larger dose achieves a larger treatment effect; or, given the same dose, a sicker population experiences a larger treatment effect than a less sick population. The quality of a body of evidence may be lower when there are no plausible explanations for inconsistent results.
Directness has multiple meanings in assessing the quality of a body of evidence. First, directness refers to the proximity of comparison in studies, that is, whether the available evidence is based on a “head-to-head” (i.e., direct) comparison of the intervention and comparator of interest, or whether it must rely on some other basis of comparison (i.e., directness of comparisons). For example, where there is no direct evidence pertaining to intervention A vs. comparator B, evidence may be available for intervention A vs. comparator C and of comparator B vs. comparator C; this could provide an indirect basis for the comparison intervention A vs. comparator B. This form of directness can apply for individual studies as well as a body of evidence.
Second, directness refers to how many bodies of evidence are required to link the use of an intervention to the impact on the outcome of interest (i.e., directness of outcomes). For example, in determining whether a screening test has an impact on a health outcome, a single body of evidence (e.g., from a set of similar RCTs) that randomizes patients to the screening test and to no screening and follows both populations through any detection of a condition, treatment decisions, and outcomes would comprise direct evidence. Requiring multiple bodies of evidence to show each of detection of the condition, impact of detection on a treatment decision, impact of treatment on an intermediate outcome, and then impact of the intermediate outcome on the outcome of interest would constitute indirect evidence.
Third, directness can refer to the extent to which the focus or content of an individual study or group of studies diverges from an evidence question of interest. Although evidence questions typically specify most or all of the elements of PICOTS (patient populations, interventions, comparators, outcomes, timing, and setting of care) or similar factors, the potentially relevant available studies may differ in one or more of those respects. As such, directness may be characterized as the extent to which the PICOTS of the studies in a body of evidence align with the PICOTS of the evidence question of interest. This type of directness reflects the external validity of the body of evidence, i.e., how well the available evidence represents, or can be generalized to, the circumstances of interest. Some approaches to quality assessment of a body of evidence address external validity of evidence separately, noting that external validity of a given body of evidence may vary by the user or target audience (Berkman 2014). Some researchers suggest that, if individual studies are to be assembled into a body of evidence for a systematic review, then external validity should be evaluated only once, i.e., when assessing the quality of the body of evidence, not at the level of individual studies (Atkins 2004; Viswanathan 2014).
Publication bias refers to unrepresentative publication of research reports that is not due to the quality of the research but to other characteristics. This includes tendencies of investigators and sponsors to submit, and publishers to accept, reports of studies with “positive” results, such as those that detect beneficial treatment effects of a new intervention, as opposed to those with “negative” results (no treatment effect or high adverse event rates). Studies with positive results also are more likely than those with negative results to be published in English, be cited in other publications, and generate multiple publications (Sterne 2001). When there is reason to believe that the set of published studies is not representative of all relevant studies, there is less confidence that the reported treatment effect for a body of evidence reflects the true treatment effect, thereby diminishing the quality of that body of evidence. Prospective registration of clinical trials (e.g., in ClinicalTrials.gov), adherence to guidelines for reporting research, and efforts to seek out relevant unpublished reports are three approaches used to manage publication bias (Song 2010).
One approach used for detecting possible publication bias in systematic reviews and meta-analyses is to use a funnel plot that graphs the distribution of reported treatment effects from individual studies against the sample sizes of the studies. This approach assumes that the reported treatment effects of larger studies will be closer to the average treatment effect (reflecting greater precision), while the reported treatment effects of smaller studies will be distributed more widely on both sides of the average (reflecting less precision). A funnel plot that is asymmetrical suggests that some studies, such as small ones with negative results, have not been published. However, asymmetry in funnel plots is not a definitive sign of publication bias, as asymmetry may arise from other causes, such as over-estimation of treatment effects in small studies of low methodological quality (Song 2010; Sterne 2011).
The use of the terms, publication bias and reporting bias, varies. For example, in the GRADE framework, reporting bias concerns selective, incomplete, or otherwise differential reporting of findings of individual studies (Balshem 2011). Other guidance on assessing the quality of a body of evidence uses reporting bias as the broader concept, including publication bias as described above and differential reporting of results (Berkman 2014). The Cochrane Collaboration uses reporting bias as the broader term to include not only publication bias, but time lag bias, multiple (duplicate) publication bias, location (i.e., in which journals) bias, citation bias, language bias, and outcome reporting bias (Higgins 2011).
Magnitude of effect size can improve confidence in a body of evidence where the relevant studies report treatment effects that are large, consistent, and precise. Overall treatment effects of this type increase confidence that they did not arise from potentially confounding factors only. For example, the GRADE quality rating approach suggests increasing the quality of evidence by one level when methodologically rigorous observational studies show at least a two-fold change in risk ratio and increasing by two levels for at least a five-fold change in relative risk (Guyatt 2011).
Plausible confounding that would diminish observed effect refers to instances in which plausible confounding factors for which the study design or analysis have not accounted would likely have diminished the observed effect size. That is, the plausible confounding would have pushed the observed effect in the opposite direction of the true effect. As such, the true effect size is probably even larger than the observed effect size. This increases the confidence that there is a true effect. This might arise, for example, in a non-randomized controlled trial (or a comparative observational study) comparing a new treatment to standard care. If, in that instance, the group of patients receiving the new treatment has greater disease severity at baseline than the group of patients receiving standard care, yet the group receiving the new treatment has better outcomes, it is likely that the true treatment effect is even greater than its observed treatment effect.
Dose-response effect (or dose-response gradient) refers to an association in an individual study or across a body of evidence, between the dose, adherence, or duration of an intervention and the observed effect size. That is, within an individual study in which patients received variable doses of (or exposure to) an intervention, the patients that received higher doses also experienced a greater treatment effect. Or, across a set of studies of an intervention in which some studies used higher doses than other studies, those study populations that received higher doses also experienced greater treatment effects. A dose-response effect increases the confidence that an observed treatment effect represents a true treatment effect. Dose-response relationships are typically not linear; further, they may exist only within a certain range of doses.
As is so for assessing the quality of individual studies, the quality of a body of evidence should be graded separately for each main treatment comparison for each major outcome for each where feasible. For example, even for a comparison of one intervention to a standard of care, the quality of the bodies of evidence pertaining to each of mortality, morbidity, various adverse events, and quality of life may differ. For example, the GRADE approach calls for rating the estimate of effect for each critical or otherwise important outcome in a body of evidence. GRADE also specifies that an overall rating of multiple estimates of effect pertains only when recommendations are being made (i.e., not just a quality rating of evidence for individual outcomes) (Guyatt 2013).
Box IV-6. A Summary of the GRADE Approach to Rating Quality of a Body of Evidence
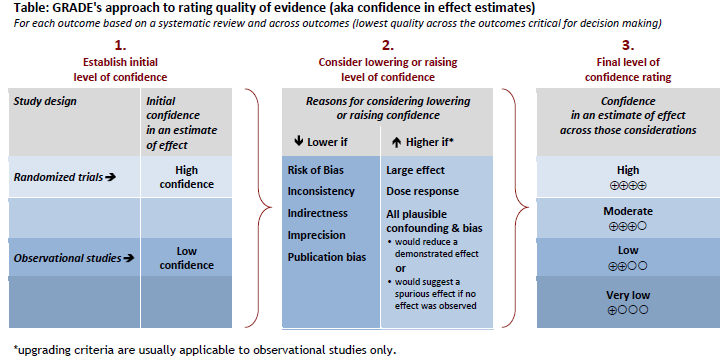
| Quality level | Current definition |
| High | We are very confident that the true effect lies close to that of the estimate of the effect |
| Moderate | We are moderately confident in the effect estimate: The true effect is likely to be close to the estimate of the effect, but there is a possibility that it is substantially different |
| Low | Our confidence in the effect estimate is limited: The true effect may be substantially different from the estimate of the effect |
| Very low | We have very little confidence in the effect estimate: The true effect is likely to be substantially different from the estimate of effect |
Reprinted with permission: GRADE Working Group, 2013. Balshsem H, et al. GRADE guidelines: 3. Rating the quality of evidence. J Clin Epidemiol. 2011(64):401-6.
Among the important ways in which appraisal of evidence quality has evolved from using traditional evidence hierarchies is the accounting for factors other than study design. For example, as shown in the upper portion of Box IV-6, the GRADE approach to rating quality of evidence (which has been adopted by the Cochrane Collaboration and others) starts with a simplified categorization of study types, i.e., RCTs and observational studies, accompanied by two main levels of confidence (high or low) in the estimate of a treatment effect. Then, the rating scheme allows for factors that would raise or lower a level of confidence. Factors that would lower confidence in evidence would include, e.g., risk of bias, inconsistency across the RCTs, indirectness, and publication bias; factors that would increase confidence include, e.g., large effect size and an observed dose-response effect. The final levels of confidence rating (high, moderate, low, very low) are shown at the right, and defined in the lower portion of that box. Similarly, the OCEBM 2011 Levels of Evidence (see chapter III, Box III-13) allows for grading down based on study quality, imprecision, indirectness, or small effect size; and allows for grading up for large effect size. Box IV-7 shows the strength of evidence grades and definitions for the approach used by the AHRQ EPCs, which are based factors that are very similar to those used in GRADE, as noted above.
Box IV-7. Strength of Evidence Grades and Definitions
| Grade | Definition |
| High | We are very confident that the estimate of the effect lies close to the true effect for this outcome. The body of evidence has few or no deficiencies. We believe that the findings are stable, i.e., another study would not change the conclusions. |
| Moderate | We are moderately confident that the estimate of effect lies close to the true effect for this outcome. The body of evidence has some deficiencies. We believe that the findings are likely to be stable, but some doubt remains. |
| Low | We have limited confidence that the estimate of effect lies close to the true effect for this outcome. The body of evidence has major or numerous deficiencies (or both). We believe that additional evidence is needed before concluding either that the findings are stable or that the estimate of effect is close to the true effect. |
| Insufficient | We have no evidence, we are unable to estimate an effect, or we have no confidence in the estimate of effect for this outcome. No evidence is available or the body of evidence has unacceptable deficiencies, precluding reaching a conclusion. |
Source: Berkman ND, et al. Chapter 15. Grading the Strength of a Body of Evidence When Assessing Health Care Interventions for the Effective Health Care Program of the Agency for Healthcare Research and Quality: An Update. In: Methods Guide for Effectiveness and Comparative Effectiveness Reviews. AHRQ Publication No. 10(14)-EHC063-EF. Rockville, MD: Agency for Healthcare Research and Quality. January 2014.
G. Consensus Development
In various forms, group judgment or consensus development is used to set standards, make regulatory recommendations and decisions, make payment recommendations and policies, make technology acquisition decisions, formulate practice guidelines, define the state-of-the-art, and other purposes. The term “consensus development” can refer to particular group processes or techniques that generally are intended to derive best estimates of parameters or general (or unanimous) agreement on a set of findings or recommendations. It also can refer to particular methodological paradigms or approaches, e.g., the consensus development conferences that were conducted by the US NIH.
In contrast to the quantitative synthesis methods of meta-analysis and decision analysis, consensus development is generally qualitative in nature. It may be unstructured and informal, or it may involve formal group methods such as the nominal group technique and Delphi technique (Fink 1984; Gallagher 1993; Jairath 1994). Although these processes typically involve face-to-face interaction, some consensus development efforts combine remote, iterative interaction of panelists (as in the formal Delphi technique) with face-to-face meetings; video and web conferencing and related telecommunications approaches also are used.
In HTA, consensus development is not used as the sole approach to deriving findings or recommendations, but rather as supported by systematic reviews and other analyses and data. Virtually all HTA efforts involve some form of consensus development at some juncture, including one or more of three main steps of HTA: interpret evidence, integrate evidence, and formulate findings and recommendations. Consensus development also can be used for ranking, such as to set assessment priorities, and for rating, such as drawing on available evidence and expert opinion to develop practice guidelines.
The opinion of an expert committee concerning, e.g., the effectiveness of a particular intervention, does not in itself constitute strong evidence. The experience of experts in the forms of, e.g., individual cases or series of cases could comprise poor evidence, as it is subject to multiple forms of bias (selection bias, recall bias, reporting bias, etc.). Where they exist, the results of pertinent, rigorous scientific studies should take precedence. In the absence of strong evidence, and where practical guidance is needed, expert group opinion can be used to infer or extrapolate from the limited available evidence. HTA must be explicit regarding where the evidence stops and where the expert group opinion begins.
Many consensus development programs in the US and around the world were derived from the model of consensus development conference originated at the US NIH in 1977 as part of an effort to improve the translation of NIH biomedical research findings to clinical practice. NIH modified and experimented with its process over the years. Especially in later years, these conferences usually involved a systematic review (such as prepared by an AHRQ Evidence-based Practice Center), in addition to invited expert speaker testimony and public (audience) testimony. The NIH program was discontinued in 2013, after having conducted nearly 130 consensus development conferences and nearly 40 state-of-the-science conferences that used a similar format. Australia, Canada, Denmark, France, Israel, Japan, The Netherlands, Spain, Sweden and the UK are among the countries that used various forms of consensus development programs to evaluate health technologies, some of which were later adapted or incorporated into HTA programs (McGlynn 1990).
Various evaluations and other reports have defined attributes or made recommendations concerning how to strengthen consensus development programs (Goodman 1990; Institute of Medicine 1990; Olsen 1995; Portnoy 2007). Much of this material has contributed to HTA and related fields that use forms of group process.
References for Chapter IV
Atkins D, Best D, Briss PA, Eccles M, et al., GRADE Working Group. Grading quality of evidence and strength of recommendations. BMJ. 2004;328(7454):1490. PubMed| PMC free article
Balk EM, Bonis PAL, Moskowitz H, et al. Correlation of quality measures with estimates of treatment effect in meta-analyses of randomized controlled trials. JAMA. 2002;287(22):2973-82. PubMed
Balshem H, Helfand M, Schünemann HJ, Oxman AD, et al. GRADE guidelines: 3. Rating the quality of evidence. J Clin Epidemiol. 2011;64(4):401-6. PubMed
Bauch CT, Li M, Chapman G, Galvani AP. Adherence to cervical screening in the era of human papillomavirus vaccination: how low is too low? Lancet Infect Dis. 2010;10(2):133-7. PubMed
Bayliss SE, Davenport C. Locating systematic reviews of test accuracy studies: how five specialist review databases measure up. Int J Technol Assess Health Care. 2008;24(4):403-11. PubMed
Berkman ND, Lohr KN, Ansari M, McDonagh M, et al. Chapter 15. Grading the Strength of a Body of Evidence When Assessing Health Care Interventions for the Effective Health Care Program of the Agency for Healthcare Research and Quality: An Update. In: Methods Guide for Effectiveness and Comparative Effectiveness Reviews. AHRQ Publication No. 10(14)-EHC063-EF. Rockville, MD: Agency for Healthcare Research and Quality. January 2014. Accessed Feb. 1, 2014 at: //effectivehealthcare.ahrq.gov/ehc/products/60/318/CER-Methods-Guide-140109.pdf.
Booth A, Clarke M, Dooley G, Ghersi D, et al. PROSPERO at one year: an evaluation of its utility. Syst Rev. 2013;2:4. PubMed | PMC free article
Borenstein M, Hedges LV, Higgins JPT, Rothstein HR. Introduction to Meta-Analysis. Chapter 43: Criticisms of meta-analysis. New York, NY: John Wiley & Sons; 2009.
Bossuyt PM, Reitsma JB, Bruns DE, Gatsonis CA, et al.; Standards for Reporting of Diagnostic Accuracy. Towards complete and accurate reporting of studies of diagnostic accuracy: The STARD Initiative. Ann Intern Med. 2003;138(1):40-4. PubMed
Buckley DI, Ansari M, Butler M, Williams C, Chang C. Chapter 4. The Refinement of Topics for Systematic Reviews: Lessons and Recommendations from the Effective Health Care Program. In: Methods Guide for Effectiveness and Comparative Effectiveness Reviews. AHRQ Publication No. 10(14)-EHC063-EF. Rockville, MD: Agency for Healthcare Research and Quality. January 2014. Accessed Feb. 1, 2014 at: //effectivehealthcare.ahrq.gov/ehc/products/60/318/CER-Methods-Guide-140109.pdf.
Caro JJ, Caro G, Getsios D, et al. The migraine ACE model: evaluating the impact on time lost and medical resource use. Headache. 2002;40(4):282-91. PubMed
Caldwell DM, Ades AE, Higgins JP. Simultaneous comparison of multiple treatments: combining direct and indirect evidence. BMJ. 2005;331(7521):897–900. PubMed | PMC free article
Counsell C. Formulating questions and locating primary studies for inclusion in systematic reviews. Ann Intern Med. 1997;127:380-7. PubMed
Deeks JJ. Systematic reviews in health care: systematic reviews of evaluations of diagnostic and screening tests. BMJ. 2001;323(7305):157-62. PubMed | PMC free article
Des Jarlais DC, Lyles C, Crepaz N; TREND Group. Improving the reporting quality of nonrandomized evaluations of behavioral and public health interventions: the TREND statement. Am J Public Health. 2004;94(3):361-6. PubMed | PMC free article.
Detsky AS, Naylor CD, O'Rourke K, McGeer AJ, L'Abbe KA. Incorporating variations in the quality of individual randomized trials into meta-analysis. J Clin Epid. 1992;45(3):255-65. PubMed
Dreyer NA, Velentgas P, Westrich K, Dubois R. The GRACE Checklist for Rating the Quality of Observational Studies of Comparative Effectiveness: A Tale of Hope and Caution. J Manag Care Pharm. 2014;20(3):301-8. PubMed | Publisher free article
Eckman MH, Levine HJ, Pauker SG. Decision analytic and cost-effectiveness issues concerning anticoagulant prophylaxis in heart disease. Chest. 1992;102(suppl. 4):538-549S. PubMed
Eddy DM. A Manual for Assessing Health Practices & Designing Practice Policies: The Explicit Approach. Philadelphia, Pa: American College of Physicians, 1992.
Eddy DM, Schlessinger L. Validation of the Archimedes diabetes model. Diabetes Care. 2003;26(11):3102-10. PubMed
Egger M, Smith GD, Altman DG, eds. Systematic Reviews in Health Care: Meta-analysis in Context. 2nd ed. London, England: BMJ Books; 2001.
Egger M, Smith GD, Sterne JA. Uses and abuses of meta-analysis. Clin Med. 2001;1(6):478-84. Pubmed
Fink A, Kosecoff J, Chassin M, Brook RH. Consensus methods: characteristics and guidelines for use. Am J Pub Health. 1984;74(9):979-83. PubMed | PMC free article
Gallagher M, Hares T, Spencer J, Bradshaw C, Webb I. The nominal group technique: a research tool for general practice? Family Practice. 1993;10(1):76-81. PubMed
Gazelle GS, Hunink MG, Kuntz KM, et al. Cost-effectiveness of hepatic metastasectomy in patients with metastatic colorectal carcinoma: a state-transition Monte Carlo decision analysis. Ann Surg. 2003;237(4):544-55. PubMed | PMC free article
Goetghebeur MM, Wagner M, Khoury H, et al. Bridging health technology assessment (HTA) and efficient health care decision making with multicriteria decision analysis (MCDA): applying the EVIDEM framework to medicines appraisal. Med Decis Making. 2012;32(2):376-88. PubMed
Gold MR, Siegel JE, Russell LB, Weinstein MC. Cost-Effectiveness in Health and Medicine. New York, NY: Oxford University Press; 1996.
Goodman C, Baratz SR, eds. Improving Consensus Development for Health Technology Assessment: An International Perspective. Washington, DC: National Academy Press; 1990. Accessed Nov. 1, 2013 at: http://www.nap.edu/openbook.php?record_id=1628&page=.
GRADE Working Group. Organizations that have endorsed or that are using GRADE. 2013. Accessed October. 29, 2014 at: http://www.gradeworkinggroup.org/society/index.htm.
Guyatt G, Oxman AD, Sultan S, Brozek J, et al. GRADE guidelines: 11. Making an overall rating of confidence in effect estimates for a single outcome and for all outcomes. J Clin Epidemiol. 2013;66(2):151-7. PubMed
Guyatt GH, Oxman AD, Sultan S, Glasziou P, et al., GRADE Working Group. GRADE guidelines: 9. Rating up the quality of evidence. J Clin Epidemiol. 2011;64(12):1311-6. PubMed
Hasselblad V, Hedges LV. Meta-analysis of screening and diagnostic tests. Psychol Bull. 1995;117(1): 167-78. PubMed
Hernandez DA, El-Masri MM, Hernandez CA. Choosing and using citation and bibliographic database software (BDS). Diabetes Educ. 2008;34(3):457-74. PubMed
Higgins JPT, Green S, eds. Cochrane Handbook for Systematic Reviews of Interventions. Version 5.1.0 [updated March 2011]. The Cochrane Collaboration, 2011. Accessed Sept. 1, 2013 at: https://training.cochrane.org/handbook.
Husereau D, Drummond M, Petrou S, Carswell C, et al.; CHEERS Task Force. Consolidated Health Economic Evaluation Reporting Standards (CHEERS) statement. Int J Technol Assess Health Care. 2013;29(2):117-22. PubMed
Institute of Medicine. Consensus Development at the NIH: Improving the Program. Washington, DC: National Academy Press; 1990. Accessed Nov. 1, 2013 at: http://www.nap.edu/openbook.php?record_id=1563&page=1.
Irwig L, Tosteson AN, Gatsonis C, Lau J, et al. Guidelines for meta-analyses evaluating diagnostic tests. Ann Intern Med. 1994;120(8):667-76. PubMed
Jairath N, Weinstein J. The Delphi methodology (part two): a useful administrative approach. Can J Nurs Admin. 1994;7(4):7-20. PubMed
Jansen JP, Fleurence R, Devine B, et al. Interpreting indirect treatment comparisons and network meta-analysis for health-care decision making: report of the ISPOR Task Force on Indirect Treatment Comparisons Good Research Practices: part 1. Value Health. 2011;14(4):417-28. PubMed
Kahn R, Alperin P, Eddy D, et al. Age at initiation and frequency of screening to detect type 2 diabetes: a cost-effectiveness analysis. Lancet. 2010;375(9723):1365-74. PubMed
Kulasingam SL, Havrilesky L, Ghebre R, Myers ER. Screening for Cervical Cancer: A Decision Analysis for the U.S. Preventive Services Task Force. AHRQ Pub. No. 11-05157-EF-1. Rockville, MD: Agency for Healthcare Research and Quality; May 2011. Accessed June 18, 2014 at: //www.ncbi.nlm.nih.gov/books/NBK92546.
Laird NM, Mosteller F. Some statistical methods for combining experimental results. Int J Technol Assess Health Care. 1990;6(1):5-30. PubMed
Lau J, Antman EM, Jiminez-Silva J, Kupelnick B, Mosteller F, Chalmers TC. Cumulative meta-analysis of therapeutic trials for myocardial infarction. N Engl J Med. 1992;327(4):248-54. PubMed | Publisher free article
Liberati A, Altman DG, Tetzlaff J, et al. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. PLoS Med. 2009;6(7):e1000100. PubMed | PMC free article
Littenberg B, Moses LE. Estimating diagnostic accuracy from multiple conflicting reports: a new meta-analytic method. Med Dec Making. 1993;13(4):313-21. PubMed
Luz PM, Vanni T, Medlock J, Paltiel AD, Galvani AP. Dengue vector control strategies in an urban setting: an economic modelling assessment. Lancet. 2011;377(9778):1673-80. PubMed | PMC free article
Lyles CM, Kay LS, Crepaz N, Herbst JH, et al. Best-evidence interventions: findings from a systematic review of HIV behavioral interventions for US populations at high risk, 2000-2004. Am J Public Health. 2007;97(1):133-43. PubMed | PMC free article.
McGlynn EA, Kosecoff J, Brook RH. Format and conduct of consensus development conferences. Multi-nation comparison. Int J Technol Assess Health Care. 1990;6(3):450-69. PubMed
Moher D, Cook DJ, Eastwood S, Olkin I, et al. Improving the quality of reports of meta-analyses of randomized controlled trials: the QUOROM statement. Quality of reporting of meta-analyses. Lancet. 1999;354(9193):1896-900. PubMed
Moher D, Liberati A, Tetzlaff J, Altman DG, The PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009;6(7): e1000097. PubMed | PMC free article.
Moher D, Pham B, Jones A, et al. Does quality of reports of randomised trials affect estimates of intervention efficacy reported in meta-analyses? Lancet. 1998;352(9128):609-13. PubMed
Nordmann AJ, Kasenda B, Briel M. Meta-analyses: what they can and cannot do. Swiss Med Wkly. 2012;142:w13518. Publisher free article
Normand SL. Meta-analysis: formulating, evaluating, combining, and reporting. Stat Med. 1999;18:321-59. PubMed
OCEBM Levels of Evidence Working Group. The Oxford 2011 Levels of Evidence. Oxford Centre for Evidence-Based Medicine. Accessed Sept. 1, 2013 at: http://www.cebm.net/index.aspx?o=5653.
Ogilvie D, Egan M, Hamilton V, Petticrew M. Systematic reviews of health effects of social interventions: 2. Best available evidence: how low should you go? J Epidemiol Community Health. 2005;59(10):886-92. PubMed | PMC free article
Olson CM. Consensus statements: applying structure. JAMA. 1995;273(1):72-3. PubMed
Pauker SG, Kassirer, JP. Decision analysis. N Engl J Med. 1987;316(5):250-8. PubMed
Petitti DB. Approaches to heterogeneity in meta-analysis. Stat Med. 2001;20:3625-33. PubMed
Philips Z, Ginnelly L, Sculpher M, Claxton K, et al. Review of guidelines for good practice in decision-analytic modelling in health technology assessment. Health Technol Assess. 2004;8(36):iii-iv, ix-xi, 1-158. PubMed | Publisher free article
Portnoy B, Miller J, Brown-Huamani K, DeVoto E. Impact of the National Institutes of Health Consensus Development Program on stimulating National Institutes of Health-funded research, 1998 to 2001. Int J Technol Assess Health Care, 2007;23(3):343-8. PubMed
Rawlins MD. On the evidence for decisions about the use of therapeutic interventions. The Harveian Oration of 2008. London: Royal College of Physicians, 2008. PubMed
Rew L. The systematic review of literature: synthesizing evidence for practice. J Spec Pediatr Nurs. 2011;16(1):64-9. PubMed
Sassi, F. Setting priorities for the evaluation of health interventions: when theory does not meet practice. Health Policy. 2003;63(2):141-54. PubMed
Savoie I, Helmer D, Green CJ, Kazanjian A. Beyond Medline: reducing bias through extended systematic review search. Int J Technol Assess Health Care. 2003;19(1):168-78. PubMed
Shea BJ, Grimshaw JM, Wells GA, et al. Development of AMSTAR: a measurement tool to assess the methodological quality of systematic reviews. BMC Med Res Methodol.2007;7:10. PubMed | PMC free article.
Shea BJ, Hamel C, Wells GA, Bouter LM, et al. AMSTAR is a reliable and valid measurement tool to assess the methodological quality of systematic reviews. J Clin Epidemiol. 2009;62(10):1013-20. PubMed
Siebert U, Alagoz O, Bayoumi AM, Jahn B, et al.; ISPOR-SMDM Modeling Good Research Practices Task Force. State-transition modeling: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force--3. Value Health. 2012;15(6):812-20. Accessed Feb. 1, 2014 at: //mdm.sagepub.com/content/32/5/690.full.pdf+html. PubMed
Slavin RE. Best evidence synthesis: an intelligent alternative to meta-analysis. J Clin Epidemiol. 1995;48(1):9-18. PubMed
Song F, Parekh S, Hooper L, Loke YK, et al. Dissemination and publication of research findings: an updated review of related biases. Health Technol Assess. 2010;14(8):iii, ix-xi, 1-193. PubMed
Sonnenberg FA, Beck JR. Markov models in medical decision making: a practical guide. Med Decis Making. 1993;13(4):322-38. PubMed
Soto J. Health economic evaluations using decision analytic modeling. Principles and practices--utilization of a checklist to their development and appraisal. Int J Technol Assess Health Care. 2002;18(1):94-111. PubMed
Stern M, Williams K, Eddy D, Kahn R. Validation of prediction of diabetes by the Archimedes model and comparison with other predicting models. Diabetes Care. 2008;31(8):1670-1. PubMed | PMC free article.
Sterne JA, Egger M, Smith GD. Systematic reviews in health care: Investigating and dealing with publication and other biases in meta-analysis. BMJ. 2001;323(7304):101-5. PubMed | PMC free article
Sterne JA, Sutton AJ, Ioannidis JP, Terrin N, et al. Recommendations for examining and interpreting funnel plot asymmetry in meta-analyses of randomized controlled trials. BMJ. 2011;343:d4002. PubMed
Stroup DF, Berlin JA, Morton SC, et al. Meta-analysis of observational studies in epidemiology. A proposal for reporting.Meta-analysis Of Observational Studies in Epidemiology (MOOSE) group. JAMA. 2000;283:2008-12. PubMed
Sutton AJ, Abrams KR, Jones DR, Sheldon TA, Song F. Systematic reviews of trials and other studies. Health Technol Assess. 1998;2(19):1-276. PubMed | Publisher free article
Thacker SB. Meta-analysis: A quantitative approach to research integration. JAMA. 1988; 259(11):1685-9. PubMed
Thokala P, Duenas A. Multiple criteria decision analysis for health technology assessment. Value Health. 2012;15(8):1172-81. PubMed
Thompson SG, Higgins JP. How should meta-regression analyses be undertaken and interpreted? Stat Med. 2002;21(11):1559-73. PubMed
Thornton JG, Lilford RJ, Johnston N. Decision analysis in medicine. BMJ. 1992;304(6834):1099-103. PubMed | PMC free article .
Turner L, Shamseer L, Altman DG, Weeks L, et al. Consolidated standards of reporting trials (CONSORT) and the completeness of reporting of randomised controlled trials (RCTs) published in medical journals. Cochrane Database Syst Rev. 2012 Nov 14;11:MR000030. PubMed
US Preventive Services Task Force. Procedure Manual. AHRQ Publication No. 08-05118-EF, July 2008. Accessed Aug. 1, 2013 at: http://www.uspreventiveservicestaskforce.org/uspstf08/methods/procmanual.htm.
van Houwelingen HC, Arends LR, Stijnen T. Advanced methods in meta-analysis: multivariate approach and meta-regression. Stat Med. 2002;21(4):589-624. PubMed
Viswanathan M, Ansari MT, Berkman ND, Chang S, et al. Chapter 9. Assessing the risk of bias of individual studies in systematic reviews of health care interventions. In: Methods Guide for Effectiveness and Comparative Effectiveness Reviews. AHRQ Publication No. 10(14)-EHC063-EF. Rockville, MD: Agency for Healthcare Research and Quality. January 2014. Accessed Feb. 1, 2014 at: //www.effectivehealthcare.ahrq.gov/ehc/products/60/318/CER-Methods-Guide-140109.pdf.
von Elm E, Altman DG, Egger M, Pocock SJ, et al.; STROBE Initiative. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. J Clin Epidemiol. 2008;61(4):344-9. PubMed
Weinstein MC, O'Brien B, Hornberger J, et al. Principles of good practice for decision analytic modeling in health-care evaluation: report of the ISPOR Task Force on Good Research Practices − Modeling Studies. Value Health. 2003;6(1):9-17. PubMed
Whiting P, Westwood M, Burke M, Sterne J, Glanville J. Systematic reviews of test accuracy should search a range of databases to identify primary studies. J Clin Epidemiol. 2008;61(4):357-64. PubMed
Page 1 of 1
Last Reviewed: April 1, 2020