

Background
What is SRA?
The Sequence Read Archive (SRA) is a collection of over 10 petabytes of user-submitted nucleotide sequencing reads, most of which are publicly available to download. Sequencing data can be submitted with structured, but unregulated, metadata to help inform users on the origins of the sequence.
You can browse the SRA using the NCBI website here: https://www.ncbi.nlm.nih.gov/sra
Sequence data can also be downloaded using a command-line tool called the SRA Toolkit. We won't use this in today's workshop, but it is the officially supported way to download SRA data in bulk.
If you want to explore the metadata of sequencing data in bulk, we strongly encourage you do so in the cloud using AWS Athena.
What is AWS Athena?

This is AWS’ database querying platform designed to rapidly parse through massive collections of data using the SQL language.
NCBI offers all SRA read metadata as a table we can easily import into Athena.
One popular use-csae for this metadata is to filter it for a list of sequences with a related origin (e.g., same host organism, same geographic origin, etc.) Today, we will Athena to help find the sequencing data associated with our case study.
When we find the information we want from Athena, we can save the results to our own computers or to another AWS service called an S3 bucket.
What is an S3 bucket?

S3 buckets are the “hard drive” of your cloud computer. These buckets can store an almost limitless amount of data. Buckets and their data can be shared with others. For example, the metadata tables NCBI provides are technically stored in an NCBI-owned S3 bucket that we have set to be shared publicly with the rest of the world. This is why they are so easily imported into AWS Athena.
Like all cloud services, you only pay for what you use. Price of an S3 bucket increases with storage size/duration and data transfer fees, but there are a variety of ways to help manage cost depending on your use case.
Today’s S3 is free!
Objective 1 Goals
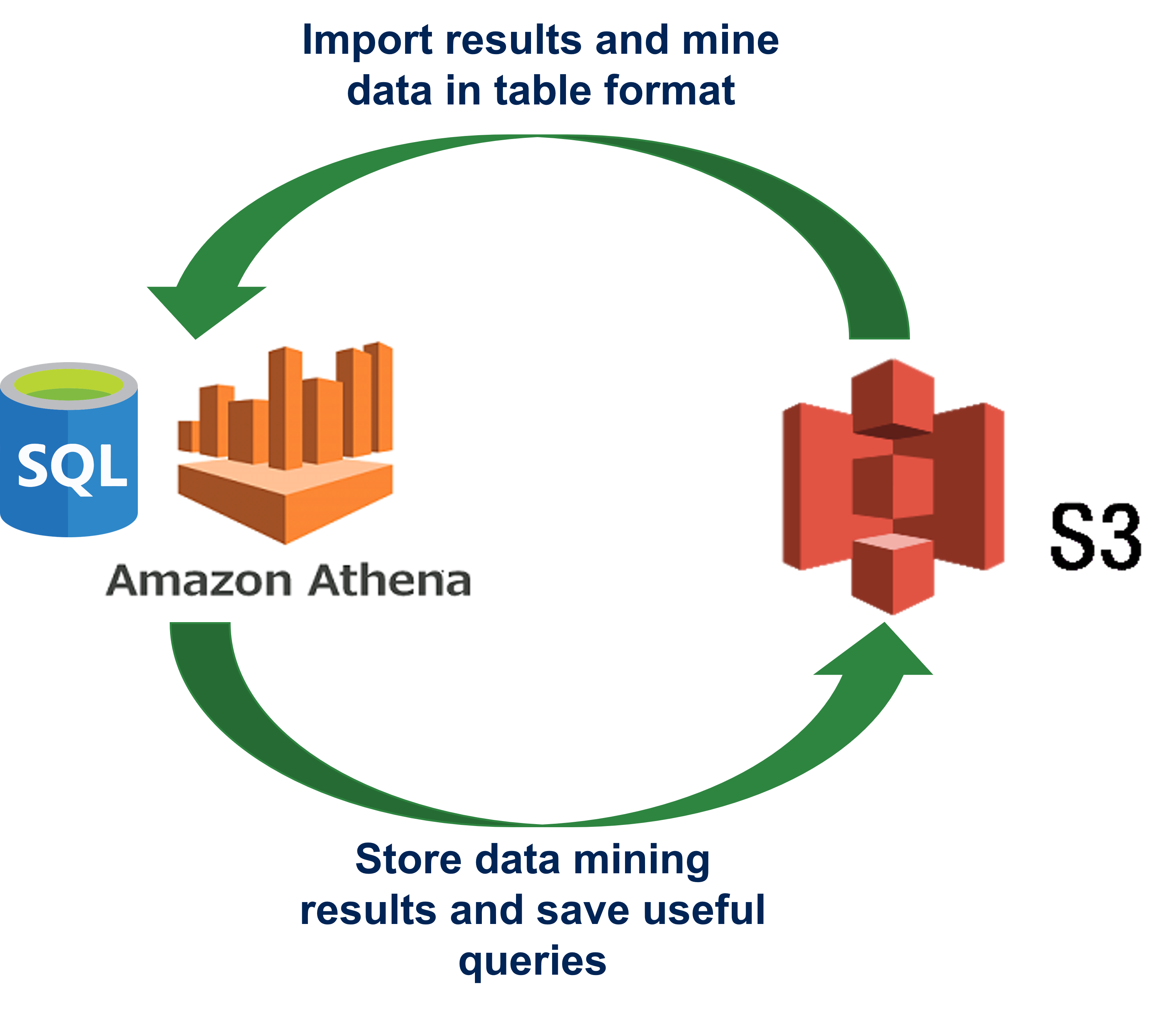
Our goal for this first objective is to essentially complete one full loop of moving data to-and-from AWS Athena and our own S3 bucket. We will first analyze data from NCBI's SRA metadata table, then save those results to our own S3 bucket for use later.
Computational
- Create an S3 bucket to store results and files
- Use basic SQL commands to query Athena data tables
- Save query results to personal computer and an S3 bucket
Case Study
- Find sequence data associated with the case study publication.
Creating an S3 Bucket
Before we can use Athena, we need to make an S3 bucket that we can save our results to as we search the SRA metadata tables. So, let’s go make one!
1) Use the search bar at the top of the console page to search for S3 and click on the first result
2) Click the orange Create Bucket button on the right-hand side of the screen
3) Enter a bucket name and make sure the region is set to US East (N. Virginia) us-east-1
S3 bucket names must be completely unique.
For this workshop, use the format <username>-cloud-workshop where <username> is the username you used to login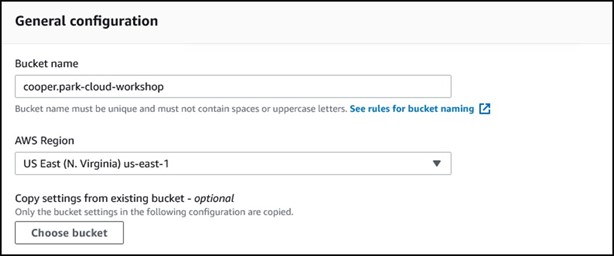
4) In the Object Ownership section, select "ACLs enabled".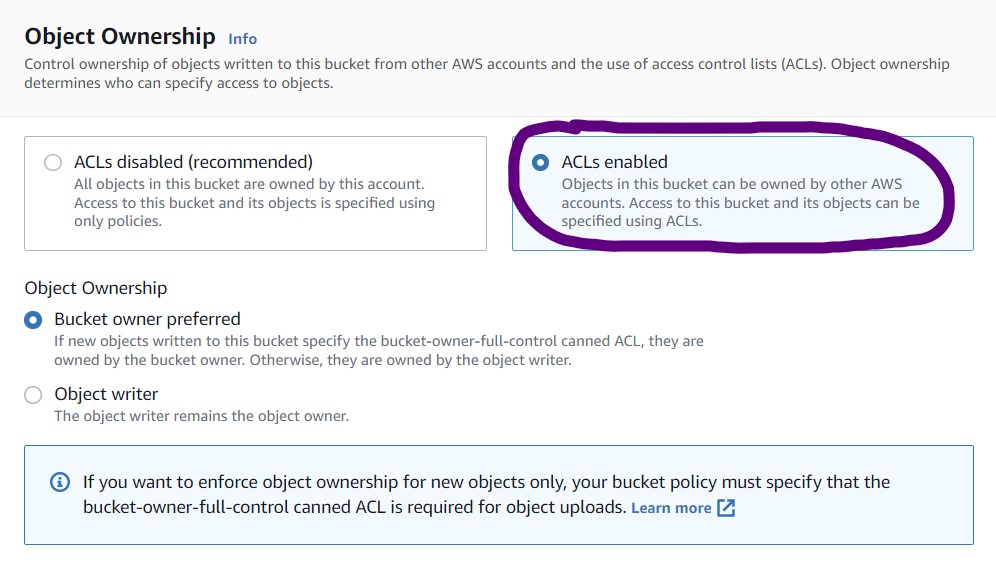
5) Scroll down to the Block Public Access settings for this bucket section. Deselect the blue checkbox at the top and check the box underneath the warning symbol to acknowledge your changes to the public access settings
NOTE: We turn on Public Access so that we can upload our files from the bucket directly to public websites like NCBI (e.g., we will be uploading result files from our bucket to the Genome Data Viewer later today). By default, you should keep your bucket from Public Access unless you explicitly need it
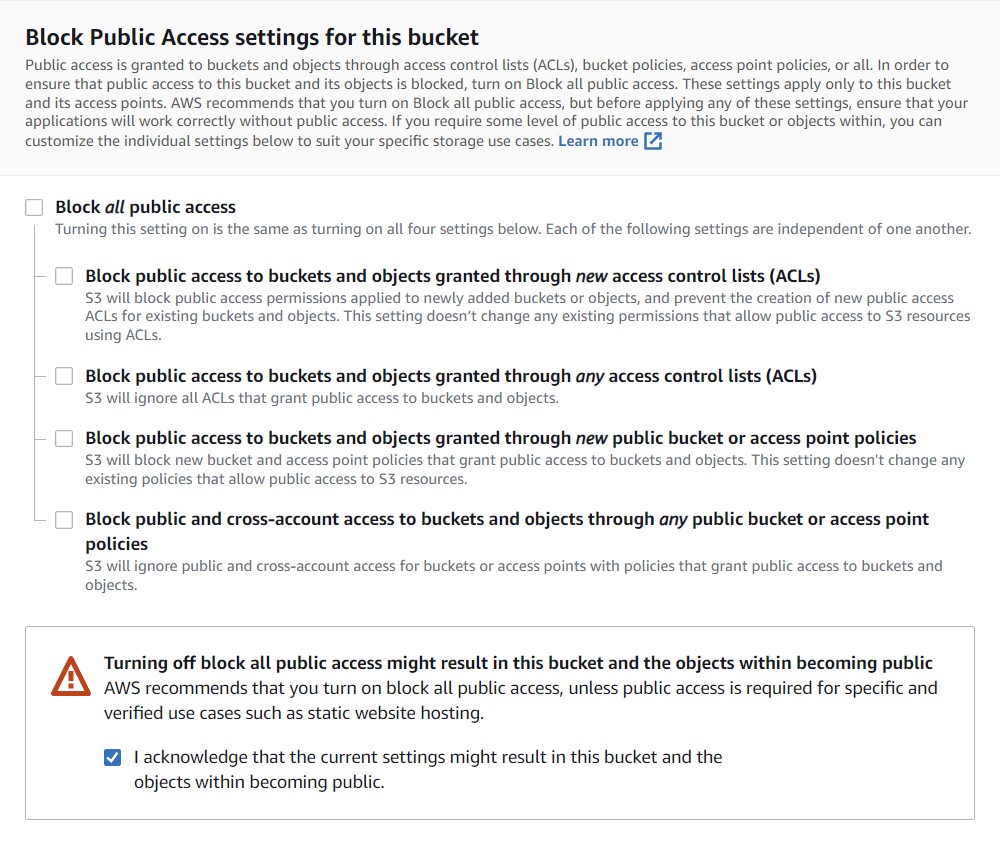
6) Ignore the rest of the settings and scroll to the bottom of the page. Click the orange Create Bucket button.
7) Clicking the button will redirect you back to the main S3 page. You should be able to find your new bucket in the list. If so, you have successfully created an S3 bucket!
Now that we have an S3 bucket ready, we can go see what the Athena page looks like!
Navigating to Athena
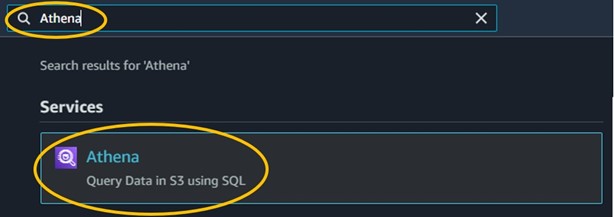
1) Use the search bar at the top of the console page to search for Athena and click on the first result
2) Visiting the Athena page should prompt you with one notification about the “new Athena console experience”. You can just click the “X” to remove it.

3) To make sure Athena saves our search results in the correct S3 bucket, we need to tell it which one to use. Good thing we just made one, eh? Click Settings in the top left of the screen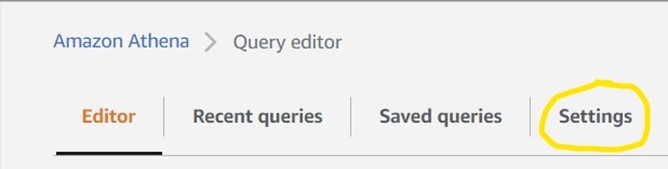
4) Click the Manage button on the right (1st image) then Browse S3 on the next page (2nd image) to see the list of S3 buckets in our account. Scroll to find your S3 bucket then click the radio button to the left of the name and click Choose in the bottom right (3rd image). Finally, click Save (4th image).

Now that we can save Athena results we are ready to do some searches! Of course, that means we need data to actually search. To do this easily, we would import the SRA metadata table using another AWS service called AWS Glue. However, to save time and resources, this has already been done prior to the workshop by the instructor.
For the detailed instructions on using AWS Glue to add a table to Athena to your own account, visit the Supplementary Text: Instructions for AWS Glue!
Exploring Athena Tables
These steps aren’t necessary to do before every Athena query, but they are useful when exploring a new table.
1) Navigate back to the Editor tab and click the dropdown menu underneath the Database section and click sra to set it as the active database. If you do not see this as an option, refresh the page and check again.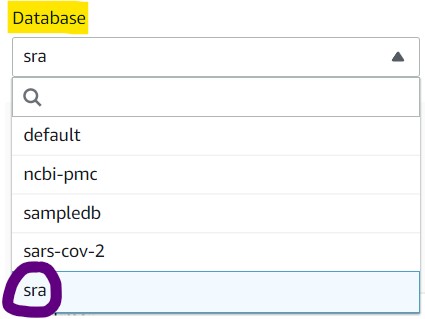
2) Look at the Tables section and click the ellipses next to the metadata table, then click Preview Table to automatically run a sample command which will give you 10 random lines from the table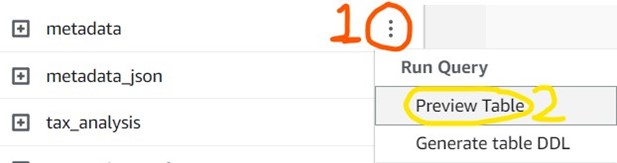
You can also click the + button next to the Metadata name to see a list of all the columns in the table.
For SRA based tables, you can also visit the following link to get the definition of each column in the table: https://www.ncbi.nlm.nih.gov/sra/docs/sra-cloud-based-examples/
Querying Our Dataset
1) The following link is the actual publication for our case study today. Scroll to the very bottom and find the Data Availability section: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5778042/
You can also use the SRA Run Selector on the NCBI website to download data from NCBI directly to your S3 bucket! Find more information and a tutorial here: https://www.ncbi.nlm.nih.gov/sra/docs/data-delivery/
2) The paper stored the data we need under and ID SRP125431, but we don’t know exactly which column that is associated with. So, scroll through the preview table we made earlier to find a column filled with similar values.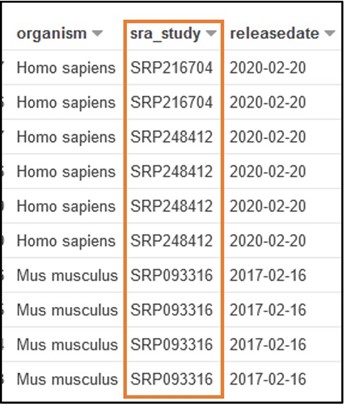
The Preview Table query we used to make this example pulls random lines from the table, so the values within your table may look different from this screenshot. The important info for us is that each value in this sra_study column starts with “SRP” (or “ERP”)
3) Now that we know which column to query for our data (sra_study), we can build the Athena query. Look to the panel where we enter our Athena queries. Click New Query 1 to navigate back to the empty panel so we can write our own query.
Fun fact: If you navigate back to Query 1 you should still see the result table for that query! Athena will save that view for you until you run a new query in that tab or close the webpage.
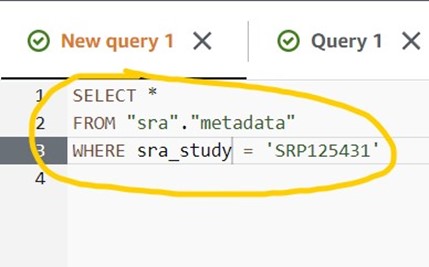
4) Copy/paste the following command into the query box in Athena (circled in yellow), then click the blue Run Query button (circled in red).
SELECT * FROM "sra"."metadata" WHERE sra_study = 'SRP125431'
5) If you see a results table with three rows like the partial screenshot below, you have successfully found your data!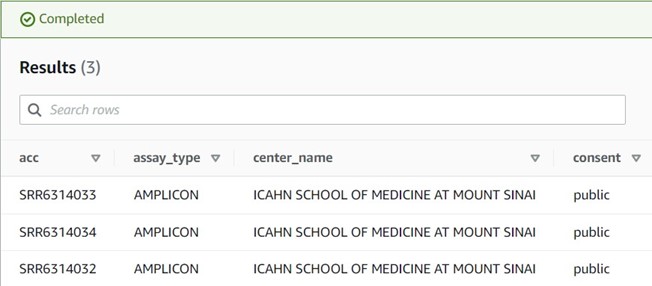
6) Click the Download results button on the top-right corner of the results panel to download your file to your computer in CSV format. You should be able to open this in Microsoft Excel, Google Sheets, or a regular text editor (e.g., Notepad for PC, TextEdit for Mac). We will review this file later, so keep it handy.
Want to challenge yourself? Visit the supplementary text (section: SQL challenges) to find some questions you can build your own SQL query for. Plus, find more advanced SQL query techniques and a deeper breakdown of the SRA metadata table too!
Page 1 of 1
Last Reviewed: July 6, 2022